Dataframe interchange protocol and Vaex
The work I briefly describe in this blog post is the implementation of the dataframe interchange protocol into Vaex which I was working on through the three month period as a Quansight Labs Intern.
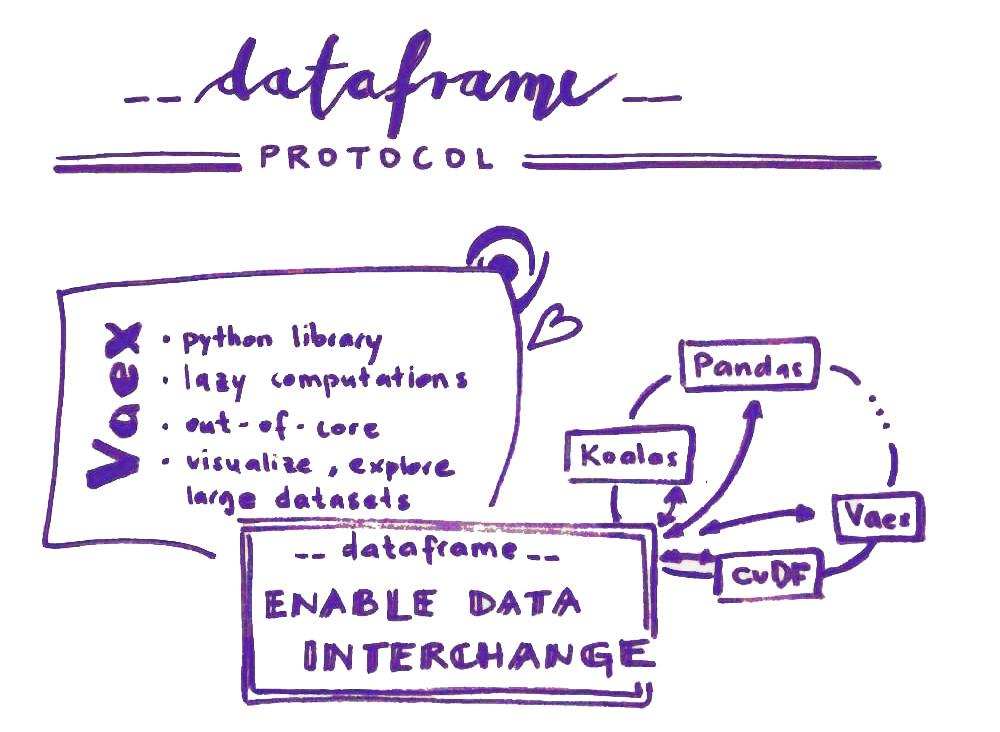 Connection between dataframe libraries with dataframe protocol
Connection between dataframe libraries with dataframe protocol
About | What is all that?
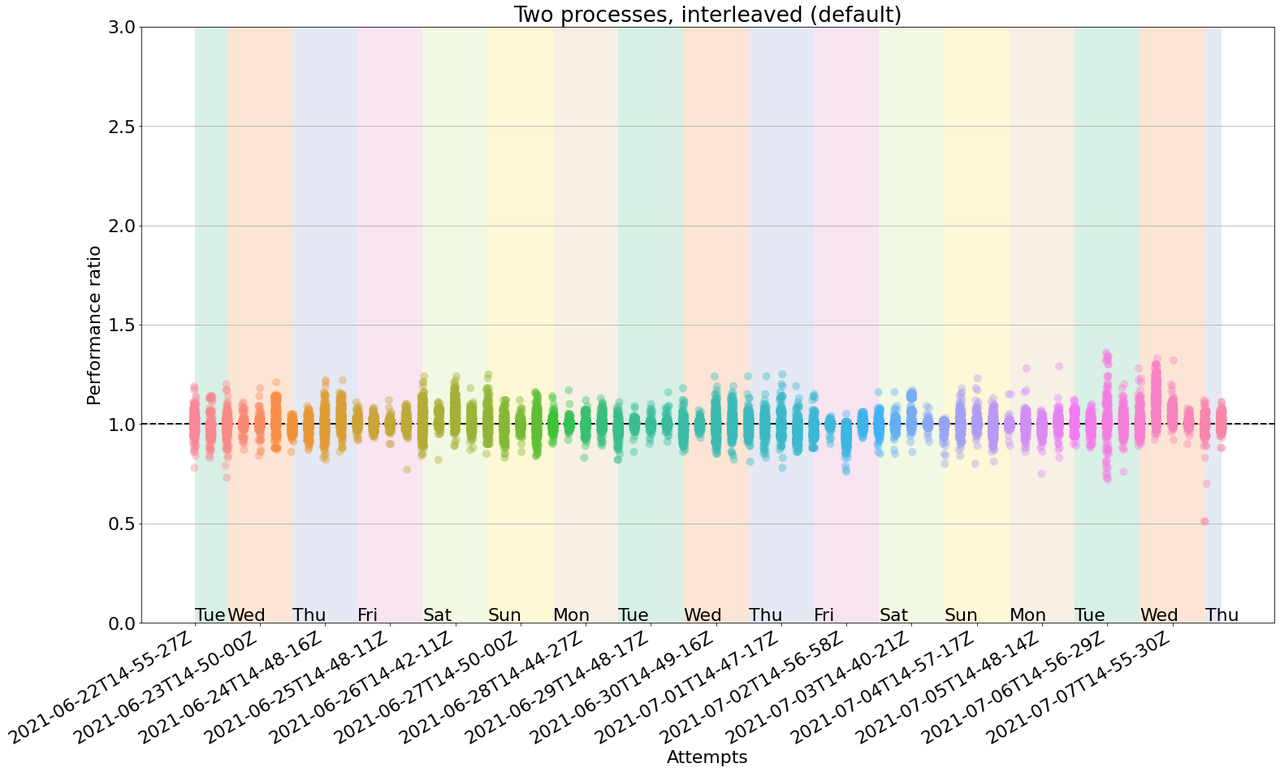
Today there are quite a number of different dataframe libraries available in Python. Also, there are quite a number of, for example, plotting libraries. In most cases they accept only the general Pandas dataframe and so the user is quite often made to convert between dataframes in order to be able to use the functionalities of a specific plotting library. It would be extremely cool to be able to use plotting libraries on any kind of dataframe, would it not?