metadsl PyData talk
metadsl PyData talk
PyData NYC just ended and I thought it would be good to collect my thoughts on metadsl based on the many conversations I had there surrounding it. This is a rather long post, so if you are just looking for some code here is a Binder link for my talk. Also, here is the talk I gave a month or so later on the same topic in Austin:
What is metadsl?
class Number(metadsl.Expression):
@metadsl.expression
def __add__(self, other: Number) -> Number:
...
@metadsl.expression
@classmethod
def from_int(cls, i: int) -> Number:
...
@metadsl.rule
def add_zero(y: Number):
yield Number.from_int(0) + y, y
yield y + Number.from_int(0), y
It's a system for creating DSLs (domain specific languages) in Python so that you can separate your API from its implementation. I wrote a previous blog post showing how to create a system like metadsl from the ground up in Python. The premise is that we are looking to a future (and present) where Python is used to build up a computation which is compiled and executed with other systems. Examples of this today are systems like Tensorflow, Numba, and Ibis.
There are currently many different approaches to writing deeply embedded DSLs in Python. metadsls main differentiator is that it piggybacks on Python's existing static typing community. All code written in metadsl should be statically analyzable with MyPy and its ilk. We define the language using Python's existing mechanisms of class and functions with type annotations. We also support writing rewrite rules, using regular Python code that is also statically analyzable. So instead of defining a separate API for describing your nodes in your graph, their signatures, and how to replace them with other nodes, you just write Python functions and expressions.
Why would we limit ourselves to essentially a restricted subset of Python's flexibility when it has such great support for flexible metaprogramming and magic? It's so that users of the library can keep the same abstractions that they know from Python. It ties it closer conceptually to the language itself and pushes any type level improvements to happen at the typing/mypy level. So that metadsl moves in accordance with the language itself. It also means we are more restricted in what we can support, but sometimes bounds are helpful to limit scope and possible options.
TLDR: metadsl is a framework to write domain specific languages in Python that piggybacks on the standard type annotation semantics.
How did your talk go?
This was my first time to present metadsl, although really a year earlier Travis and I co-presented on a previous incarnation of the project. I imagine at some point the recording will be published, but until then you can run through my talk by playing with this notebook on Binder. I appreciated the opportunity to try to place this project in some historical context. I think once I got to the actual code example though, I could have done a better job actually explaining how the system worked and what its limitations are. But it did give me leaping off point to have many great conversations with folks afterwards, which I will summarize below.
What are the remaining technical hurdles?
Many! :D
Debugging
I was very glad to bump into Martin Hirzel again. He presented a great poster at PLDI a year and a half ago, outlining some issues with using a variety of probabilistic programming libraries in Python. Each, for example, has their own abstractions for things like arrays or variables, that users have to re-learn as they switch between them. Users also don't get the same sort of debugging or tracebacks when using these libraries, as they do with regular Python, which leads to a worse user experience.
But he was here at PyData presenting a new system, called Lale, which allows you to declaratively specify your machine learning pipeline and leave out hyperparameters which you don't know. Then you can feed this to an automatic meta learning system like TPOT which will optimize these. Watch for him on a future Open Source Directions webinar presenting this work!
We talked about how we might add better debugging to metadsl. Ideally, we would be able to track back errors to the line where the user entered the expression. So even if they compile to say LLVM, and the code throws some error, it would be good to point out that error to where the user originally wrote the code. To do this, we would have to track the file, line, and column for every expression creation and propagate those along as we do replacements. We should look to Swift for some guidance here, because I know they have spent some effort making sure their compiler preserves source location as it compiles.
Mathematical soundness
Another person asked a good question after the presentation, "What if two rules match? Which gets chosen?" At the moment it's a manual process, where you define groups of rules that all should fire at the same time, so should be confluent and then put those groups in series. Like a number of compiler passes. However, we can't prove that two rules won't both match the same objects, leading to indeterminism, or that there are enough rules defined so that the result will actually be replaced, leading to an error. It would be nice to be able to say these things statically.
For example, here is an optimization rule that should execute before, say, compiling to LLVM rules:
@metadsl.rule
def add_zero(y: Number):
"""
Replace y + 0 with y
"""
yield Number.from_int(0) + y, y
yield y + Number.from_int(0), y
There is lots of existing research in the pattern matching and lambda calculus community on being able to answer these questions. However, to get to those systems it would be good to first make our pattern matching system more restricted. Currently, we can define "pure" rules, which have strictly structural matching, and "unpure" rules which execute arbitrary Python functions to determine the replacement. The unpure rules will be very hard to reason about mathematically, unless we decide to model all of Python, which seems like a bad idea. So if we can move more, if not all, of our system to pure replacements then we can have more luck analyzing them. I have a couple of ideas here:
- One use case for unpure functions is to check if a certain python value has some property. Like checking if a integer is 0 to execute some optimization. Even if we don't wanna be able to prove anything about the actual details of these properties, we could model them as pre-checks for the substitution based on deterministic functions on the values.
- Another is to wrap/unwrap from values in the host language of Python. We need this at the edges of the system, for example to unwrap tuples or replace based on which Python type is found. I don't think we can avoid this part. However, by making sure we limit it to the edges, we could still possibly prove things about the inside of the system.
- We also embed a simply typed lambda calculus into the language itself and implement beta reduction by replacing variables in the subtree. Beta reduction is impure, because we are doing a recursive find and replace on the subtree. Creation, from a Python function, is impure not only because it calls a Python callable, but also because it generates a "Variable" with a unique ID to save as the param for the function.
- In order to compile a functional data flow expression to an imperative control flow graph we need to order our expressions. More details can be found in "Optimizing compilation with the Value State Dependence Graph" paper. It's hard for me at the moment to imagine this kind of transformation in a pure pattern replacement.
For these last two, we should talk to folks from the term rewriting and lambda calculus communities. In particular, the "International Conference on Formal Structures for Computation and Deduction" seems like an appropriate venue to look into:
FSCD covers all aspects of formal structures for computation and deduction from theoretical foundations to applications. Building on two communities, RTA (Rewriting Techniques and Applications) and TLCA (Typed Lambda Calculi and Applications), FSCD embraces their core topics and broadens their scope to closely related areas in logics, models of computation (e.g. quantum computing, probabilistic computing, homotopy type theory), semantics and verification in new challenging areas (e.g. blockchain protocols or deep learning algorithms).
There is also a long history of approaches in trying to compile simply typed lambda calculus using term rewriting systems.
Python Control Flow
It was really nice to meet Joe Jevnik for the first time. He has a ton of experience hacking on Python to make things faster and was one of the original contributors to the Blaze project at Continuum.
Currently, metadsl creates expressions just by executing Python functions. This is nice and simple, but it doesn't let us map Python control flow, like if, for, and list comprehensions, to a functional form. Joe said we could modify the CPython interpreter to be able to transform these things (codetransformer). I like this method more than AST or bytecode parsing since it should work without access to the source and we don't need to put our computation in a function.
Tiark Rompf and some folks at Google have been exploring a similar space, in their "The 800 Pound Python in the Machine Learning Room" paper and snek-LMS repo:

This is a great area of future work, exploring how we can map Python control flow to metadsl expressions to get closer to the expressiveness of things like Numba or Tensorflow. It's much nicer for users to be able to write if: .... else: ... instead of a functional if_(true_clause, false_clause).
Where should this be used?
This was the second time talking to Mati Picus about this work. He works on NumPy as well as PyPy so has an interesting perspective on how tools like this could make it easier to create alternative runtimes for Python. One major difference between this work and PyPy is that we are limiting ourselves here to creating and compiling domain specific languages in Python, instead of all of Python. Not only does this mean we can deal with a restricted object model, but we can also co-design our libraries to work with this system. PyPy's job is much harder, having to interpret the full complexity of Python and the creative ways existing libraries use it.
MLIR
He also was wondering about the relationship with MLIR, a new project from Chris Lattner and Google to provide a meta-IR to describe translations between things like the Tensorflow Graph and LLVM. I was really excited to see this announced last year at the Compilers for Machine Learning conference, because it made me think that maybe this whole "lets share infrastructure to describe our IRs even if we know we need multiple ones" isn't totally crazy. I see metadsl as another take on the same idea, but focusing on Python first friendliness whereas with MLIR you use C++ (at least this is what I have seen so far).
I do want to investigate it though and see what are the main differences. One key question I have is, "Can you make a simply typed lambda calculus dialect in MLIR?" metadsl was designed to allow this to facilitate compiling things like the Mathematics of Arrays which represents arrays as functions from indices to values.
It would be nice to see if we could convert between MLIR dialects and metadsl. And long term, if we could open a dialogue there and come together into one system in the end, that would be ideal!
I have already started experimenting with translating metadsl types into JSON with the typez project. That's useful because then we could possibly generate these typez descriptions from MLIR dialects and then from there auto-generate Python code. Or vice versa.
I think for now we should focus on doing something useful with metadsl first, to really stress test it, then we can come back and see how to bridge that gap.
Dataframes
Which brings me to the most practically relevant conversations... Dataframes!
I was excited to reconnect with Marc Garcia, after meeting him a few years ago at SciPy. Congratulations to him for being awarded the Project Sustainability award at the NumFOCUS Summit the weekend before PyData NYC! He ran a docs sprint for Pandas that drew 500 people and is mentoring 26 women new to contributing to Pandas.
We talked about how we could think about targeting different backends and optimizing Pandas. His notion is that they are already exploring this for small chunks of computation. Like adding a backend flag to some larger operations to run them through different systems. They just implemented this for plotting as well. He said to move Pandas anywhere, it has to be incremental, that a full rewrite would be less likely to succeed.
I was also thrilled to meet Jeff Reback for the first time. Jeff heroically helps manage the Pandas and Ibis projects, answering your issues and merging your pull requests. If you haven't heard of Ibis yet, it's a lazy Pandas project that can target different backends, like SQL databases. At Quansight, Ivan Ogasawara has implemented a backend for the OmniSci GPU database, so that you can run queries over millions of rows very quickly from Python with a familiar API. This seems like a nice project to see if metadsl has legs.
We should take a look at C# LINQ for inspiration here, to see how they had to update their type system to support it. We will have to also upstream some of these changes to Python's core typing.
Long term implications
By describing our APIs with metadsl we transform our code into structured data.
Reproducible Science
Then, if we save this data, we are able to later analyze it semantically. For example, we can determine what data files were used to produce a certain visualization in a notebook if we output the computation graph alongside the result. This dovetails with work we have been doing in JupyterLab to support viewing linked data with Paco Nathan, the NYU Coleridge Initiative, and CalPoly.
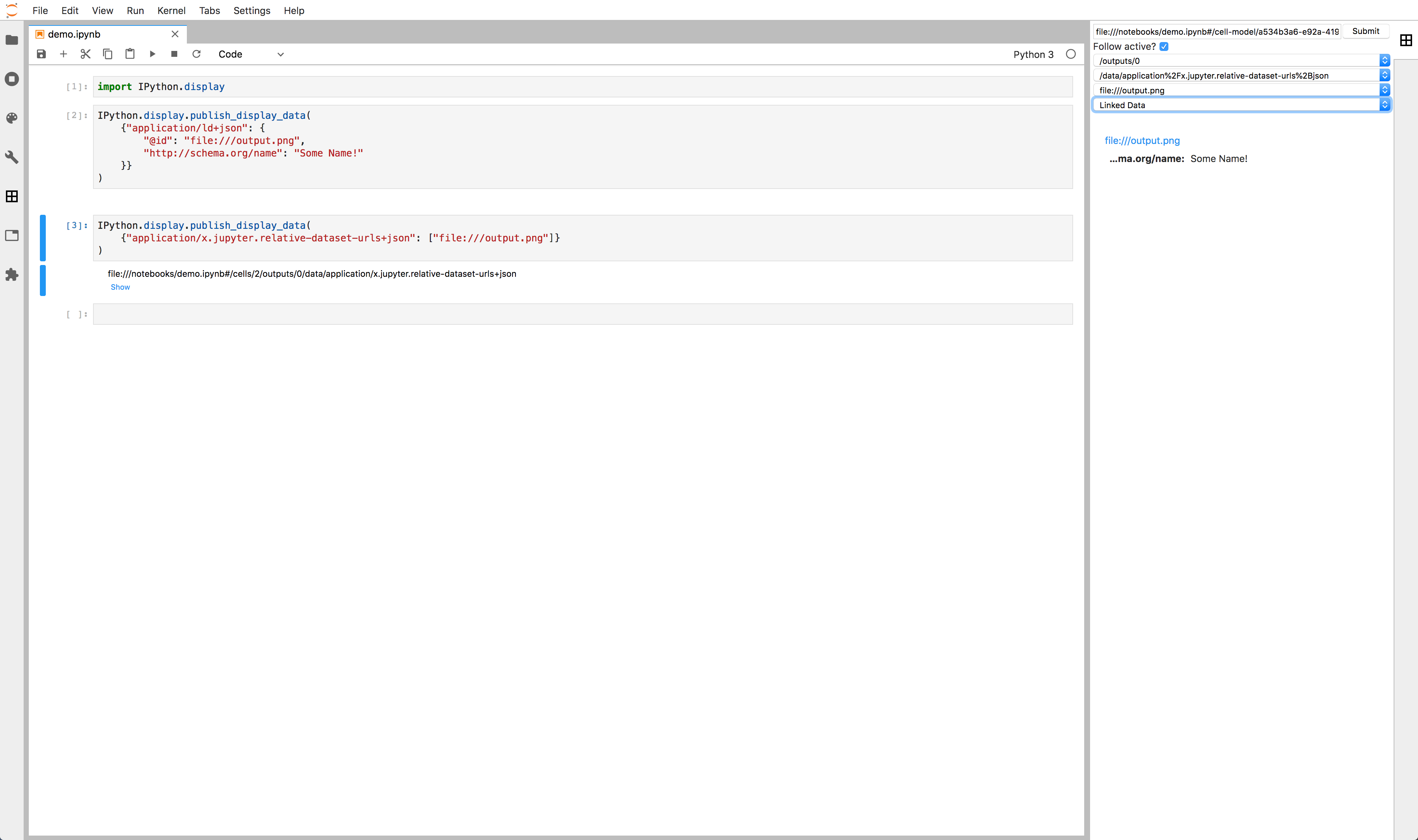 .
.
I sadly missed the talk by Evan Patterson on "Semantic modeling of data science code" also at PyData that seemed to be going down this same route, but instead by creating separate schemas for the API code. The difference here is that if libraries adopt metadsl then we get a defined ontology for free.
Statistical Code Optimizations
By creating an extensible rewrite and compilation system we make it possible to experiment with new types of whole-program optimizations on existing codebases. We are starting to see an increase in machine learning in the compilation process itself (Tensor Comprehensions, TVM, "Machine Learning in Compiler Optimization"). As our hardware and software stacks get more complicated it becomes harder to reason about optimization strictly from first principles. So we can use tools from statistics, like Bayesian Optimization, to optimize our compilation.
I went to a talk last week by David Blei, a pioneer in the probabilistic models and causal inference space. Causal inference lets us try to understand the effect of actions based on previous data from the world:

I would love to experiment with these tools to help users compile fast code across different architectures, but first we need to create space in the eocsystem to prototype them and get them into users' hands.
Wanna get involved?
This project is at an early state and would benefit from collaboration. If you want to get involved, please open an issue on the repo or reach out to me directly. As a Python ecosystem I hope we can come together to work towards solutions in this space.
Comments