

The Array API Standard in SciPy
Published October 4, 2023


lucascolley
Lucas Colley
In this blog post I discuss how SciPy is harnessing the power of array-agnostic code to become more interoperable, and why that matters.
Hi 👋 I'm Lucas Colley, a Computer Science & Philosophy student from the UK. This summer, I have had the amazing opportunity of working under the mentorship of Ralf Gommers, Pamphile Roy and Irwin Zaid in my Open Source internship at Quansight Labs. My project was to make progress towards SciPy's goal of adopting support for the array API standard, which will allow users to use SciPy functions with CuPy arrays, PyTorch tensors and potentially many other array/tensor libraries in the future.
This post stands on the shoulders of giants, including Anirudh Dagar's blog post "Array Libraries Interoperability" (from which my illustration takes much inspiration!) and Aaron Meurer's SciPy 2023 talk "Toward Array Interoperability in the Scientific Python Ecosystem"; for details of wider interoperability efforts and the array API standard, I urge you to check out those links!
Here, I approach the topic from the focused perspective of a SciPy contributor. I hope that this post will be helpful for anyone who wants to contribute to SciPy's efforts to support the array API standard.
SciPy and the Scientific Python Ecosystem
SciPy is one part of a wide collection of Open Source tools, written in Python, which are fundamental to a range of work which relies on manipulating numbers with computers. This collection is known as the Scientific Python Ecosystem - a term which broadly encompasses Open Source Python projects which are community driven and used for science (see scientific-python.org for more information).
NumPy is the n-dimensional array library which SciPy is built to work with - it is SciPy's only non-optional runtime dependency. At the time of writing, the vast majority of SciPy functions only work when providing NumPy arrays, despite the various interoperability efforts so far (see Anirudh's blog post). The main problem with this is that "NumPy provides an array implementation that’s in-memory, CPU-only and single-threaded." The potential performance improvements that could be won with parallel algorithms, support for distributed arrays and support for GPUs (and other hardware accelerators) are huge, and thus "SciPy has had 'support for distributed and GPU arrays' on its roadmap" for five years now. For more information, see this page on the use cases of the array API, and the blog post: "A vision for extensibility to GPU & distributed support for SciPy, scikit-learn, scikit-image and beyond" by Ivan Yashchuk and Ralf Gommers.
Due to these performance wishes, many different 'array provider' libraries, such as CuPy and
PyTorch, have been developed, with support for one or more of these hardware use-cases in mind.
However, due to the fact that 'array consumer' libraries are typically built to be compatible with
only one array provider library, many functions have been reimplemented in different consumer libraries,
just to work with a different provider library.
In extreme cases, this has led to efforts to reimplement entire consumer libraries,
for example cupyx.scipy.
This constant reimplementation of the same functionality has led many to see the Scientific Python Ecosystem
as rather being fractured into many smaller ecosystems, one built around each array library, and to dream for a
world where the ecosystems are unified and everything works together!
While it would certainly be a very ambitious goal to aim for everything working together, the goal of increasing interoperability between array libraries is one with widespread support. There are currently many hurdles which users can run into when navigating this fractured ecosystem. They may find that they want to convert between different array provider libraries in their projects, in order to make use of the full range of tools which have been developed. However, for many projects, frequent conversion between provider libraries is a complete no-go: cross-device copying (e.g. from GPU to CPU when converting from CuPy to NumPy) can be a huge performance hit, and other features, such as automatic differentiation, can be lost in conversion.
For users who decide to use a different provider library to take advantage of performance benefits, they can find themselves needing to learn new APIs to accomplish the same tasks, which are often similar but frustratingly different to those which they are used to. There are also likely to be gaps in the functionality offered by the libraries, which can lead back to the problem of converting between libraries, or require the user to find new ways to complete the same task. For large existing projects, this makes the prospect of switching to a different provider library a very daunting one.
On the developer side of things, it seems like there is a lot of wasted time in reimplementing the same functionality for many different provider libraries. Developer time is very valuable since these projects are still largely maintained by volunteers (and hence large tasks like adding GPU support can stay on the roadmap for many years), so work to reduce the overall maintenance load is key to accelerating progress. If each piece of functionality only needed to be implemented once and worked with any array library, then there would be many fewer projects to maintain, and much more time to work on implementing brand new functionality. Fortunately, there has been work on a standard which will help push us towards this imagined future.
The Array API Standard
The Consortium for Python Data API Standards has created the Python array API standard, which is a "specification for what it means for a library to have an ‘array API’" (see Aaron's talk). The Consortium was formed in 2020 by a group of maintainers and industry stakeholders - see the paper accompanying Aaron's talk for more information. Array consumer libraries can write 'array-agnostic' code which is compatible with this specification, rather than any particular provider library's API, and it will work with any provider library which complies with the standard. NumPy, CuPy and PyTorch are all planning to be fully compliant - with this being one of the goals for NumPy 2.0 - and JAX and Dask also have implementations in progress. The consortium has also developed array-api-compat, a small wrapper around each array library (currently NumPy, CuPy and PyTorch), which, for practical purposes, is fully compliant with the standard.
This means that array consumer libraries are able to start writing and testing array-agnostic code today.
For a NumPy-consuming library like SciPy, this has opened the opportunity to implement support for CuPy and
PyTorch by adding support for the standard via array-api-compat.
SciPy support for the array API
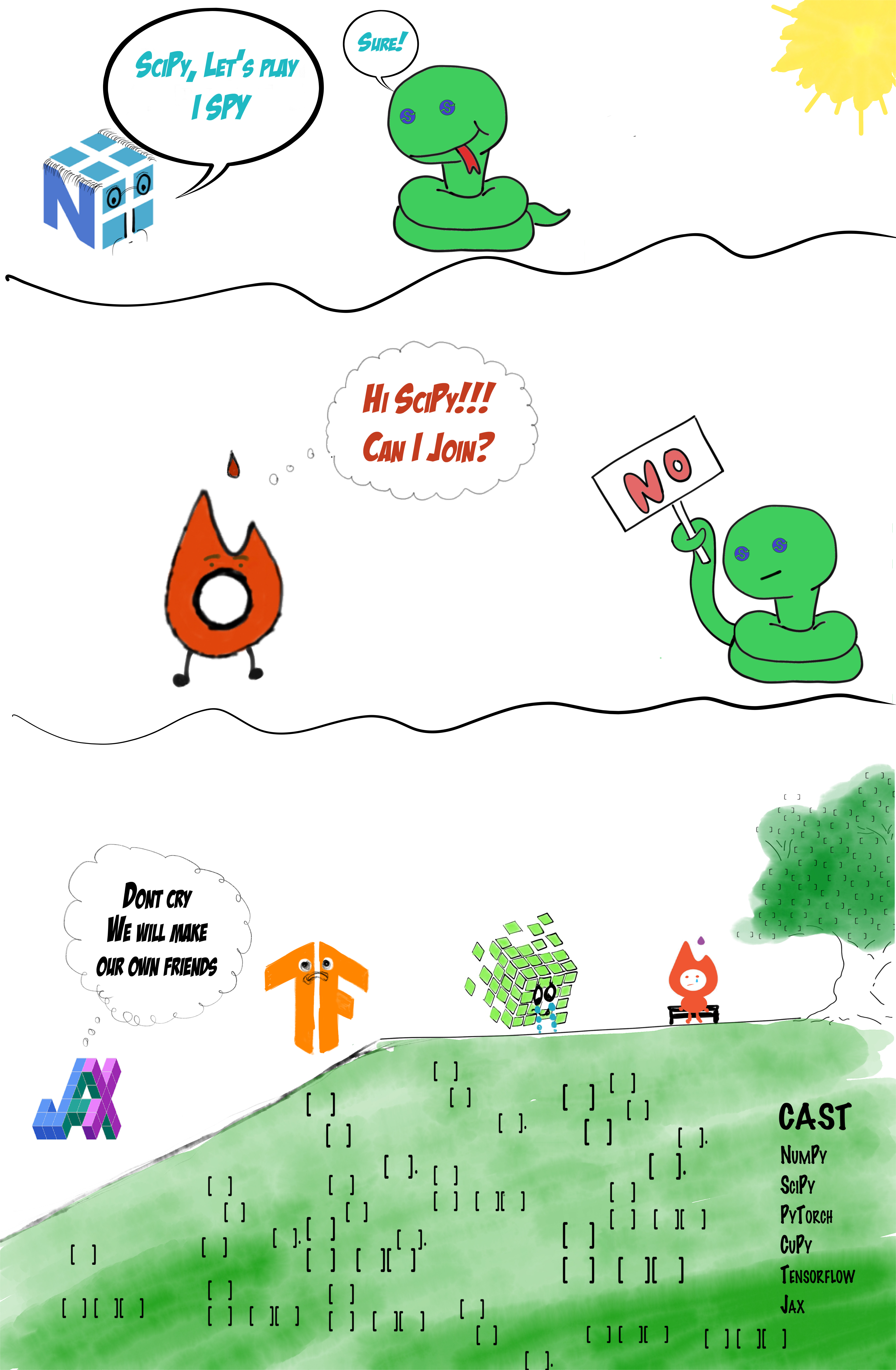
Before these interoperability efforts started, SciPy did not work well with provider libraries other than
NumPy at all (as expressed by
this amazing illustration
from Anirudh's blog post).
For example, when trying to use scipy.fft.fft with a CuPy array, users would be hit with this error message:
>>> import scipy>>> import cupy as cp>>> scipy.fft.fft(cp.exp(2j * cp.pi * cp.arange(8) / 8))…KeyError: 'ALIGNED is not defined for cupy.ndarray.flags'
Adopting the standard is the first step towards a future where users who have programs made up of SciPy functions can simply change the provider library used for their input data, and have the rest of the program still work the same, while taking advantage of any benefits of the new provider library.
To kick off the process of this work, the request-for-comment (RFC) issue
"SciPy array types & libraries support" was opened.
This set out the basic design principle of "container type in == container type out", as well as a
detailed plan for how to treat different array inputs, and the development strategy.
To summarise, the scope of the work is to treat all array inputs as specified in the RFC and to convert all
existing pure Python + NumPy code to be array API compatible.
Out of scope is converting the C/C++/Cython/Fortran code which is used within SciPy.
Behind the scenes, SciPy provides Python APIs for low level functions which are written in other languages and for the
CPU only.
These APIs are made to work with NumPy arrays - they will definitely not work for arrays on a different device to the CPU,
and are not guaranteed to work with other types of array on the CPU.
For these functions which use compiled code, some dispatching mechanism seems like the right solution, but no particular
implementation or development strategy has been settled on yet - see the discussion of uarray in
Anirudh's blog post and
the RFC for more information.
Near the start of my internship,
the first PR to convert a SciPy submodule, by Pamphile Roy, one of my mentors,
was merged, with scipy.cluster being covered (modulo a few minor follow-ups).
This PR added a lot of machinery (which I will explore in more detail later) to enable conversion and testing,
while keeping the new behaviour behind an experimental environment variable.
My main goal was to convert scipy.fft, SciPy's Fast Fourier Transform module.
fft is an
array API standard extension module,
which means that array provider libraries supporting the standard can choose to implement it or not.
scipy.fft's backend is mostly written in C++, but thanks to the extension module, we were able to convert all
of the standard extension functions to be compatible with all libraries which:
- comply with the standard
- implement the
fftextension
After the main PR merged, the ability to use CuPy arrays and PyTorch tensors
with the standard extension functions was enabled when the experimental environment variable SCIPY_ARRAY_API is set to 1.
For example, the code in the following benchmark - the task of smoothing an image (taking a 2-D image,
using scipy.fftn, zero-ing out the highest frequency components, and using scipy.ifftn) using CuPy
arrays - now works:
import scipyimport cupy as cpcpface = cp.asarray(face)f = scipy.fft.fftn(cpface)fshift = scipy.fft.fftshift(f)original = cp.copy(fshift)fshift[354:414, 482:532] = 0f_ishift = scipy.fft.ifftshift(original - fshift)x = scipy.fft.ifftn(f_ishift)
On my machine (AMD Ryzen 5 2600 & NVIDIA GeForce GTX 1060 6GB), this demonstrated a ~15x performance improvement over using NumPy arrays in the same functions. You can see the full benchmark on the PR.
Completing this PR wasn't without difficulty, as lots of SciPy's brand new array API testing infrastructure
needed improvements in the process.
I contributed quite a few PRs to help make this testing infrastructure more robust and squash some bugs;
you can find all of my merged contributions relating to array types
in this filtered view of SciPy's PR tracker.
This was also my first ever big contribution to Open Source, so there was a large (but very rewarding!) learning
process with Git, GitHub and collaboration with reviewers.
In the next section, I'll dive into the process of converting scipy.fft and share some of the lessons learned
for converting other submodules.
How to convert a submodule
I'll start by showing what the necessary changes look like, before explaining in more detail how some of the machinery works. Production functions can be divided into three categories, each with different conversion steps: those which just use pure Python and NumPy, those which use compiled code, and those which implement functions found in standard extension modules.
Pure Python + NumPy code
For functions which are made up of pure Python and NumPy, the conversion process is really quite simple!
It involves comparing the currently used functions/methods with those in
the standard API specification
and mimicking the current behaviour.
The key step is the addition of xp = array_namespace(x, y), where x and y (and so on for more inputs)
are the input arrays.
This line is used at the start of every converted function, and allows us to use the functions/methods which
are compatible with the arrays without re-importing anything!
The rest of the changes are mostly replacing uses of np with xp, alongside making adjustments where the
standard API differs from the NumPy API.
For example, here are the modifications made to scipy.fft.fht:
def fht(a, dln, mu, offset=0.0, bias=0.0):+ xp = array_namespace(a)+ # size of transform- n = np.shape(a)[-1]+ n = a.shape[-1] # example of a change where the standard offers only one way of doing things, while NumPy has more ways # bias input array if bias != 0: # a_q(r) = a(r) (r/r_c)^{-q} j_c = (n-1)/2- j = np.arange(n)- a = a * np.exp(-bias*(j - j_c)*dln)+ j = xp.arange(n, dtype=xp.float64)+ a = a * xp.exp(-bias*(j - j_c)*dln) # compute FHT coefficients- u = fhtcoeff(n, dln, mu, offset=offset, bias=bias)+ u = xp.asarray(fhtcoeff(n, dln, mu, offset=offset, bias=bias)) # transform- A = _fhtq(a, u)+ A = _fhtq(a, u, xp=xp) # bias output array if bias != 0: # A(k) = A_q(k) (k/k_c)^{-q} (k_c r_c)^{-q}- A *= np.exp(-bias*((j - j_c)*dln + offset))+ A *= xp.exp(-bias*((j - j_c)*dln + offset)) return A
Compiled code
For functions which hit compiled code, the standard isn't enough anymore.
For now, we attempt to convert to NumPy using np.asarray before the compiled code, then convert back to our
array's namespace using xp.asarray after it.
This will raise exceptions for arrays on a different device to the CPU, as justified in
the RFC (tldr: we want to avoid silent device transfers).
Here is an example from scipy.fft's Discrete Sine and Cosine Transforms, where _pocketfft is the backend
which SciPy uses for NumPy arrays:
def _execute(pocketfft_func, x, type, s, axes, norm, overwrite_x, workers, orthogonalize): xp = array_namespace(x) x = np.asarray(x) y = pocketfft_func(x, type, s, axes, norm, overwrite_x=overwrite_x, workers=workers, orthogonalize=orthogonalize) return xp.asarray(y)def dctn(x, type=2, s=None, axes=None, norm=None, overwrite_x=False, workers=None, *, orthogonalize=None): return _execute(_pocketfft.dctn, x, type, s, axes, norm, overwrite_x, workers, orthogonalize)
As a side note, there has also been work to support the calling of some specific backends instead of hitting
compiled code in scipy.special (in this PR),
which enables GPU support for at least some provider libraries.
I will keep this blog post focused on just array-agnostic code since this work in special should ultimately be
replaced by a more robust dispatching mechanism, whereas the array-agnostic code is here to stay!
Using standard extension modules
Despite this limitation on GPU support, as mentioned above, fft is a standard extension module, so the standard can still help us with some
compiled code!
For the functions in the extension, we can check whether the array's namespace implements the extension with
if hasattr(xp, 'fft'), and use xp.fft if so.
Since NumPy has an fft submodule, we need to be careful to still use SciPy's implementation for NumPy arrays,
for which we have the is_numpy helper.
Here is how that looks for scipy.fft.fft:
def _execute_1D(func_str, pocketfft_func, x, n, axis, norm, overwrite_x, workers, plan): xp = array_namespace(x) if is_numpy(xp): return pocketfft_func(x, n=n, axis=axis, norm=norm, overwrite_x=overwrite_x, workers=workers, plan=plan) norm = _validate_fft_args(workers, plan, norm) if hasattr(xp, 'fft'): xp_func = getattr(xp.fft, func_str) return xp_func(x, n=n, axis=axis, norm=norm) x = np.asarray(x) y = pocketfft_func(x, n=n, axis=axis, norm=norm) return xp.asarray(y)def fft(x, n=None, axis=-1, norm=None, overwrite_x=False, workers=None, *, plan=None): return _execute_1D('fft', _pocketfft.fft, x, n=n, axis=axis, norm=norm, overwrite_x=overwrite_x, workers=workers, plan=plan)
Tests
After converting the production functions, we also need to convert the tests.
We have the @array_api_compatible decorator, which parametrizes xp with the
available backends that we have for testing.
We have also written three new array-agnostic assertions - xp_assert_close, xp_assert_equal and xp_assert_less -
which incorporate checks for matching namespaces and dtypes.
If any tests use results or input data from NumPy, we convert everything to the xp namespace before using
these assertions.
The assertions make use of functions from xp where possible which helps to minimise the amount of device transfers.
Other than that, we make similar changes to those in the production functions so that every test works
with all of the backends with which we test.
Finally, for tests of functions which hit compiled code, we add the @skip_if_array_api_gpu decorator.
Here is what that looks like for one of the Discrete Sine and Cosine Transforms tests:
+ @skip_if_array_api_gpu+ @array_api_compatible @pytest.mark.parametrize("func", ['dct', 'dst', 'dctn', 'dstn']) @pytest.mark.parametrize("type", [1, 2, 3, 4]) @pytest.mark.parametrize("norm", [None, 'backward', 'ortho', 'forward'])- def test_fftpack_equivalience(func, type, norm):+ def test_fftpack_equivalience(func, type, norm, xp): x = np.random.rand(8, 16)+ fftpack_res = xp.asarray(getattr(fftpack, func)(x, type, norm=norm))+ x = xp.asarray(x) fft_res = getattr(fft, func)(x, type, norm=norm)- fftpack_res = getattr(fftpack, func)(x, type, norm=norm)- assert_allclose(fft_res, fftpack_res)+ xp_assert_close(fft_res, fftpack_res)
Enabling and testing with non-NumPy arrays
I'll talk a bit about implementation details now - feel free to skip this section if you are just here for an overview!
When we call array_namespace, a little more is done than just returning the namespace.
If the environment variable SCIPY_ARRAY_API is not set, array_api_compat.numpy
(the compatible wrapper for numpy) is returned, regardless of the type of the input array.
This allows us to retain all pre-array API behaviour unless the user has set the environment variable,
since the arrays are caught by our if is_numpy(xp) code path.
If it isn't set, we raise exceptions for known-bad subclasses
(as set out in the RFC),
like NumPy MaskedArrays and object arrays.
After that, we retrieve the namespace using array_api_compat.array_namespace.
The current testing infrastructure allows us to test with PyTorch (CPU & GPU) and CuPy through the command line.
For example, python dev.py test -b pytorch tests with PyTorch, and python dev.py test -b all tests with
NumPy, numpy.array_api, CuPy and PyTorch.
numpy.array_api is a strict minimal implementation of the
standard, which allows us to make sure that our array-agnostic code is really array-agnostic -
if our tests pass for numpy.array_api, then they will pass for any fully compliant library.
Testing with PyTorch on different devices can be enabled by setting the environment variable SCIPY_DEVICE to
different values: 'cuda' for Nvidia GPUs or 'mps' for MacOS devices with the Metal framework.
For more information on the implementation details, see the SciPy "Support for Array API" documentation.
Status
At the time of writing, SciPy has two of its submodules, cluster and fft, converted
(in the sense I have described above).
linalg and signal have partial coverage in progress, and some of the compiled-code functions in special
have been covered, with additional calling-out to CuPy, PyTorch and JAX.
The tracker issue
should be kept up to date with progress as more submodules are converted.
We currently support CuPy and PyTorch through array-api-compat, with Dask and JAX on the horizon.
The great thing is that whenever a provider library complies with the standard, it will work with our
converted submodules, without SciPy even needing to know that it exists!
Looking to the future
I have opened the first PR for scipy.linalg
which covers the functions which are part of
the linalg standard extension module.
In the short term, we hope to see PRs covering the rest of the submodules and continued refinement of our
testing infrastructure.
Looking further ahead for SciPy, once all libraries which we want to support comply with the standard, we can drop
array-api-compat and get the namespaces directly from the input arrays (via the __array_namespace__ attribute).
As mentioned above, a general dispatching mechanism will hopefully materialise down the line to allow full support for all functions which use compiled code. Still, even without it, a great deal of interoperability is ready to be achieved now!
Finally, I'd like to say some words about my experience as an intern at Quansight Labs and as a member of the SciPy community.
Going from having never contributed to Open Source to feeling proficient as a contributor, and having significant contributions merged towards a bleeding-edge project, has been a challenging but very special experience! Regular meetings with my mentors and the community meant that I was always able to ask questions when I was confused, and learn about the array types project and SciPy as a whole. At Quansight Labs, I was part of a cohort of interns and we also met regularly to discuss our achievements and explain where we were stuck. Sometimes, just putting your difficulties into words can help you figure things out from a different perspective!
After joining the SciPy community as part of my internship, I am keen to contribute voluntarily in the future and help to sustain science in this way. Knowing that my code will be used in a package as widely depended on as SciPy is a big motivation, and I am invested in the success of the array API standard now!
Acknowledgements
I would like to thank my mentors Ralf Gommers, Pamphile Roy and Irwin Zaid for their incredible support and guidance during my internship! I feel very lucky to have had the opportunity to learn from them in such a practical way. I would also like to thank the SciPy community, especially Tyler Reddy and Matt Haberland who have been greatly involved in the review process of many of my PRs, and Melissa Weber Mendonça who hosted many of the community meetings which I attended (as well as coordinating the internship program at Quansight Labs!).
References
- The array API standard
- "Python Array API Standard: Toward Array Interoperability in the Scientific Python Ecosystem" SciPy 2023 Talk
- "Python Array API Standard: Toward Array Interoperability in the Scientific Python Ecosystem" Paper
- "SciPy array types & libraries support" RFC
- "Array Libraries Interoperability" Blog Post
- array-api-compat
- Tracker Issue for array API support in SciPy


{kind=link}