

Python Wheels: from Tags to Variants
Published August 13, 2025


mgorny
Michał Górny
Python Wheels: from Tags to Variants
For the past 6 months we have been working hard on “wheel variants”, in collaboration with Astral, NVIDIA and the PyTorch release team. This work culminated in last week's PyTorch 2.8 release with new wheels supporting the variant design, and a corresponding experimental variant-capable release of the uv package manager. The user-facing features you can try out today are described in the blog posts from other participants:
- “A variant-enabled build of uv” by Astral
- “Streamline CUDA-Accelerated Python Install and Packaging Workflows with Wheel Variants” on the NVIDIA Technical Blog
- “PyTorch Wheel Variants, the frontier of Python Packaging” on the PyTorch Foundation blog
This blog post tells the story of how they came into being.
Introduction
Many Python distributions are uniform across different Python versions and platforms. For these distributions, it is sufficient to publish a single wheel that can be installed everywhere. However, some packages are more complex than that; they include compiled Python extensions or binaries. In order to robustly deploy these software on different platforms, you need to publish multiple binary packages, and the installers need to select the one that fits the platform used best.
For a long time, Python wheels
made do with a relatively simple mechanism to describe the needed variance:
Platform compatibility tags.
These tags identified different Python implementations and versions,
operating systems, and CPU architectures. Over time, they were extended
to facilitate new use cases. To list a couple: PEP 513
added manylinux tags to standardize the core library dependencies on GNU/Linux
systems, and PEP 656 added
musllinux tags to facilitate Linux systems with musl libc.
However, not all new use cases can be handled effectively within the framework of tags. To list a few:
- The advent of GPU-backed computing made distinguishing different acceleration frameworks such as NVIDIA CUDA or AMD ROCm important.
- As the compatibility with older CPUs became less desirable, many distributions have set baselines for their binary packages to x86-64-v2 microarchitecture level, and Python packages need to be able to express the same requirement.
- Numerical libraries support different BLAS/LAPACK, MPI, OpenMP providers, and wish to enable the users to choose the build matching their desired provider.
While tags could technically be bent to facilitate all these use cases, they would grow quite baroque, and, critically, every change to tags needs to be implemented in all installers and package-related tooling separately, making the adoption difficult.
Facing these limitations, software vendors have employed different solutions to work around the lack of an appropriate mechanism. Eventually, the WheelNext initiative took up the challenge to design a more robust solution.
The limits of platform compatibility tags
Platform compatibility tags are pretty powerful and cover a surprisingly wide range of use cases, perhaps even beyond what they were initially meant to support. Each wheel features three platform tags:
- A Python tag specifying the required Python implementation and version
- An ABI tag specifying the required Python implementation ABI for extension modules in the package
- A platform tag specifying the compatible platform (usually operating system and CPU architecture)
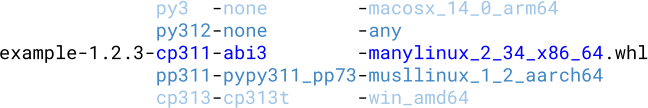
Where it gets really interesting is how different projects make use of various tag combinations. For example, a single package could combine the following conventions:
-
cp311-abi3-manylinux_2_34_x86_64uses CPython's stable ABI (abi3), in the version compatible with CPython 3.11 or newer (cp311). It is compatible with GNU/Linux systems with glibc 2.34 or newer, on x86-64 architecture (all that is encoded in themanylinux_2_34_x86_64platform tag). This is the wheel that will be used on most of the CPython versions on the given platform. -
pp311-pypy311_pp73-manylinux_2_34_x86_64designates a wheel built for PyPy 3.11 (pp311) versions usingpypy311_pp73ABI on the same platform. Wheels like these are targeting specific Python interpreter versions. They are used when the stable ABI is not used. Since some implementations, such as PyPy or the freethreading CPython builds, do not support the stable ABI, these are the wheels providing support for them. -
py3-none-anydesignates a wheel compatible with any Python 3.x version, on any platform. It means a pure Python wheel, hence for pure Python packages this is the only wheel needed. It can also be provided for packages with optional extension modules, as a fallback when no other wheel is compatible with the user's system.
You can find some unorthodox uses too, such as:
-
A pure Python package including dedicated code for every Python version, for example using
py312-none-anyto designate a wheel dedicated to Python 3.12 (or newer; though in this case newer Python versions have their own wheels). -
A pure executable package (that does not use the Python API), for example using
py3-none-macosx_11_0_arm64to designate a wheel compatible with any Python 3 implementation on a macOS 11.0+ system with ARM64 CPU.
Tags clearly provide some degree of flexibility. The logic already present in installers can usually account for future Python versions, operating system versions, libc versions, and to some degree for new implementations, ABI changes, new architectures and so on. But can it manage entirely novel tags?
Well, technically yes. Some use cases would fit well within the current platform
tags. Say, we could replace the plain manylinux_2_28_x86_64 tag with a more
fine-grained manylinux_2_28_x86_64_v3. Properties that aren't exclusive
to existing platforms could be appended to them; say,
manylinux_2_28_x86_64_cuda129, manylinux_2_28_aarch64_openblas_openmpi
and so on. However, there are two major problems with that.
First, the existing pip code, based on the packaging library, relies on enumerating all tag combinations compatible with the specific system, and comparing the tags found in wheels to that list. For example, on a GNU/Linux system with Python 3.14 and glibc 2.41, it yields almost 1300 combinations. While this number does not pose a problem yet, once we start adding multiple additional suffixes, the number of possible combinations explodes.
Second, tags are implemented entirely within the package manager. This implies that for every new set of tags, all package managers must add support for them, and then their users must upgrade. And ideally, the tags would be defined in such a way that the implementation will be able to predict and support future tags. Otherwise, we're talking about having to update all the package managers every time a new CPU or GPU architecture version is defined, or a new CUDA version is released, and so on.
While the first problem can be resolved by optimizing the algorithm, the second cannot. In other words, while tags serve their primarily purpose well, they don't scale.
How did projects manage without new tags?
It's not like this problem cropped up overnight. Packages have needed more variants than platform tags supported for a while now, so how are they working around the problem?

If you enter PyTorch's “Start Locally”
document, you are welcomed with an interactive chooser. Once you select
a specific build, operating system and compute platform, you are given
a specific pip invocation. Most of these commands include an --index-url
parameter, and that's the answer: different variants of PyTorch wheels
are published on separate package indexes, rather than on PyPI.
Surely, this isn't the most optimal solution. For a start, it requires additional effort from the user.
In the first place, you need to realize that you can't just
pip install torch and necessarily get what you expected. You need to find
the instructions, and follow them. And for your PyTorch installation
to be correctly updated in the future, you also need to continue
using the custom index.
And this assumes you are actually installing PyTorch directly. If it is only a dependency of something else, you may not even notice that it is being installed!
Furthermore, the more packages use similar approaches, the more custom indexes you end up using. And if different indexes start providing different versions of the same packages, the results can get pretty surprising. In fact, this led to the work on PEP 766, in an attempt to improve security when using multiple indexes (currently in draft).
Let's look at another example. JAX's “Supported Platforms” matrix provides links to instructions for different installation options.
Most of them suggest installing the jax package
with an “extra” specified, e.g.: jax[cuda12]. And indeed, JAX provides support
for different variants through plugins that can be pulled in automatically
via dependencies. This avoids using additional indexes, but still requires
additional effort from the user.
Other variations of the same solution are possible. Rather than using plugins, CuPy uses different package names for the variants. However, this has the unfortunate side effect that once multiple different variants end up being installed, they may overwrite one another.
Or one can just publish a single package with all possible variants inside, at the price of massively increasing the wheel sizes, which is highly undesirable, and for projects like PyTorch it is going to exceed PyPI's size limits.
Plugins to the rescue!
As I have already pointed out, the solutions that put variant selection entirely within the package manager aren't very flexible. They could only work if the list of valid variants is largely fixed, or at least predictable. To sidestep this limitation, we need a more distributed architecture, one where each package can independently devise how to select between its variants. This is how we reached an architecture based on plugins.
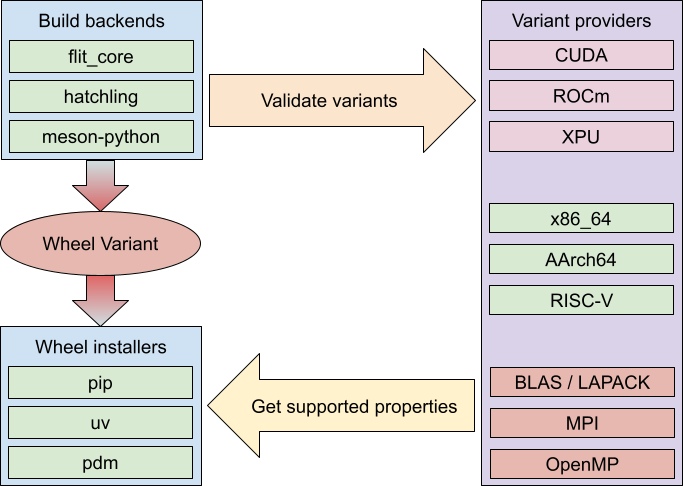
While build backends (as defined by PEP 517) remain responsible for building wheels, and installers for selecting and installing wheels, they both defer variant-related tasks to external variant providers. These are regular Python packages that can be maintained and updated independently of the installers, and therefore are able to deal with the rapidly developing variant landscape better. Everyone can create their own provider, and every package can declare which providers they precisely need; and installers automatically use them on demand.
Now, this kind of flexibility requires a slightly different approach than tags. After all, a single variant can be described using a number of properties, such as: CUDA or ROCm runtime version, compatible GPU architectures, compatible CPU architectures, required instruction sets, selected libraries, and so on. While some variants could be described using tag-style short strings, making them fully scalable requires using more general property lists.
Expressing these properties in a key-value form seemed like a good idea.
That is, rather than having a dozen property tags such as cuda_lower_12_5,
cuda_lower_12_6, cuda_lower_12_7 and so on, we'd rather have a single
feature name cuda_version_lower_bound and the version as a value. And since
we expect variant providers to be developed largely independently, putting
these features in namespaces makes it possible to organize them logically
and avoid name collisions. Consider the example in listing 1.
nvidia :: cuda_version_lower_bound :: 12.6nvidia :: cuda_version_upper_bound :: 13x86_64 :: level :: v3x86_64 :: sha_ni :: on
Yes, the syntax was inspired by trove classifiers! Every property is a 3-element tuple consisting of the namespace (one for each plugin), feature name and value.
Here, two providers are used: one representing CUDA installation (nvidia
namespace) and one representing x86_64 CPU properties (x86_64 namespace).
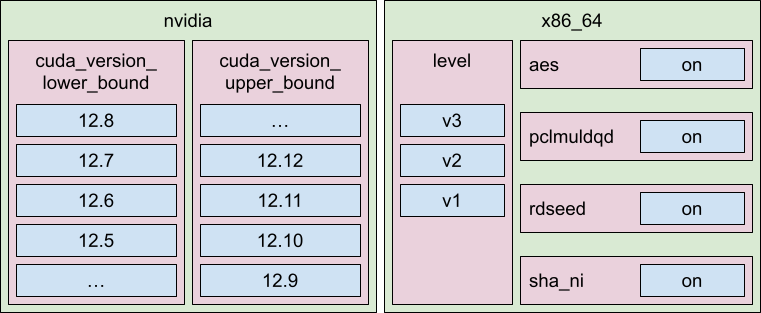
The nvidia provider detects the local CUDA installation and determines which version
is installed. Then, it transforms this version into a set of compatible
constraints that can be used to determine whether a given wheel variant
can be installed, and if multiple variants fit, which one should be used.
For example, if you have CUDA 12.8, then all wheels that do not require a newer
CUDA version are installable, but a wheel built specifically
for CUDA 12.8 will be preferred. So, wheels with a lower bound
of 12.8, 12.7, 12.6, 12.5 and so on, are allowed. The upper bound is handled in a similar way.
The x86_64 provider detects the local CPU, and determines which instruction sets
are supported. Then it returns all compatible x86-64 architecture levels,
and all supported instruction sets. So if you have a CPU supporting x86-64-v3,
the plugin would return v3, v2 and v1 as compatible, plus a long list of supported
instruction set flags that can be used to indicate specific requirements
above the baseline implied by level.
From exhaustive enumeration to JSON
Much like with tags, the installer needs to know the wheel variant's properties to select a wheel to install. However, these properties can both be more numerous and more complex than tags, and therefore are not a good fit to be included in the filename.
Fetching all the wheels is not an option, as they can be quite large. Now, technically the Zip format allows for relatively optimal partial fetching, so we could just fetch the relatively small amount of data related to variant properties. Still, fetching data from a possibly large number of wheel variants could hardly be considered an optimal solution, and not all indexes support HTTP range requests that are required for this.
Variant wheels do need unique filenames though, and at the same time we wanted to avoid making them too long. Some existing wheel filenames are long enough already to be causing issues for some users.
Here, the inspiration came from Conda's build strings. Much like Conda packages usually include a hash of build variables, in their build string, we have decided to use a hash of variant properties to uniquely identify variants.
An additional advantage of this solution is that the hashing algorithm provided a reproducible mapping from properties to wheel filenames. In the first demo implementation of variant wheels, we used this property to select variants without actually fetching their properties. Instead, the installer would query all plugins found installed, for their supported properties, then enumerate all possible combinations, compute their hashes and match them against available variant wheels.
Unfortunately, this solution had a number of disadvantages. Most importantly, with growing number of supported properties, the number of possible combinations grew exponentially. With more complex plugins, hash computation quickly became a bottleneck. For example, after modeling 20 trivial properties (for SIMD instruction sets), dependency resolution already slowed down by over 10 seconds on a consumer-grade system. Modeling 40 flags would exceed a billion possible combinations, and require tebibytes of memory for the hash table. On top of that, the approach assumed that the user needs to know which plugins to install first. So while it was an interesting idea, it did not scale well.
So we did the next best thing: added an explicit file with variant information that is published alongside variant wheels. And from this point onwards, a bunch of really interesting changes around the design started happening.
If I may jump the chronology a bit at this point, one interesting fact was how
this file affected variant information and configuration format. As the design
evolved, it was only natural that variants.json would contain not only
a mapping of available variants to their properties, but also other information
needed to use variants: how to install and load the plugins, and how to sort
the properties. Some of this information was also needed to build wheel
variants, so rather than expecting variants.json
to be maintained separately, we included all these details in project's sources
and passed them through the wheels, making it possible to generate variants.json automatically.
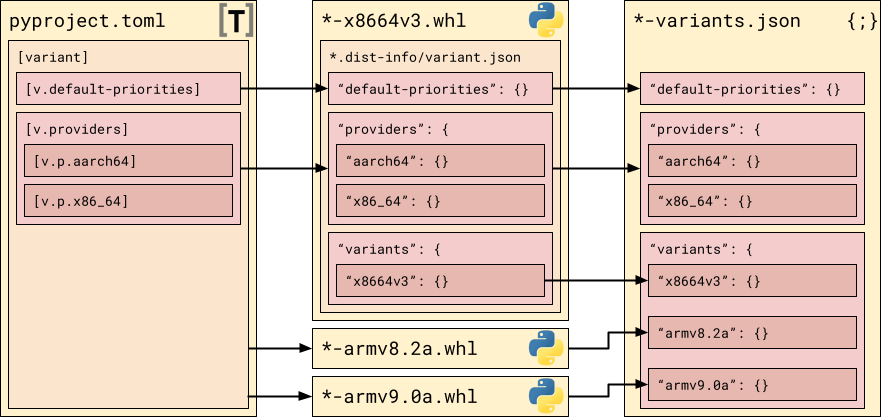
We arrived at a three step pipeline that remains at the core of the design: developers put
the baseline variant information in pyproject.toml; it is
then copied to the wheel itself, along with the metadata specifying which variant
this wheel is; and eventually the information from all wheel variants are combined
into a single *-variants.json file.
The individual file formats themselves evolved quite a bit. Initially,
the variant information in the wheel was stored in a horrid form
of Core Metadata
fields. Later, we realized we can make things much simpler by aligning
the formats between the three files. In the final design, the pyproject.toml
table is converted 1:1 into a variant.json file inside the wheel (with
variant properties added); and then variant.json files from different wheels
are merged into *-variants.json.
Finally, one more change occurred. While initially we used a single
variants.json file per directory, presumably holding combined information
for multiple package versions, eventually we switched to using separate
{distribution}-{version}-variants.json files, one per version, with their
names effectively matching the initial parts of wheel filenames.
torch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-ce71ef3b.whl // variant hashtorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu129.whl // custom label
Another useful advantage of statically defining the variant mapping was that
it enabled more arbitrary variant labels, i.e. the identifiers found in wheel
filenames. Since they no longer needed to be predictable from variant
properties, we could permit custom labels, and store a mapping
from variant labels to their properties inside *-variants.json
(previously, hashes were used as the mapping keys). Listing 2. provides
an example of how this improved the readability.
The opt-in/opt-out debate, plugin installation and discovery
Perhaps the hottest discussion point during the work on wheel variants was whether the architecture should be opt-in or opt-out. In other words, whether the users should be required to perform some explicit action before having a wheel variant installed, or whether the installer should take care of everything, including installing and running the plugins on demand.
The very first version of the proposal used a kind of opt-in mechanism. Variantlib, our reference implementation, discovered and used all plugins that were installed in the environment where the package installer was run. In order to install a variant, you had to manually install all the required plugins first. Therefore, having the plugin installed worked as a gating mechanism.
Why would we want an opt-in solution? The most important reason is security.
The variant plugin is a Python package that executes arbitrary code
during dependency resolution, possibly with elevated privileges. In fact,
the rationale of PEP 427,
the original specification of the wheel format, pointed out this very problem
with installing from source distributions: running arbitrary code to
build-and-install
.
Unfortunately, an opt-in solution like that poses a few problems. For a start, it is quite inconvenient to users. You have to realize that you need to do something special, you need to find the instructions and you need to install the plugins. And it won't always be obvious: as I've mentioned already, you won't always be directly installing PyTorch or NumPy, but you will be getting them installed as an indirect dependency. You may not even realize that they were installed, let alone that you missed an important step required to get an optimized variant. Besides, it made it easy to install an incompatible version of a plugin, two conflicting plugins, or even reach an unsolvable situation where two different packages have conflicting provider dependencies.
At the same time, plugin discovery was done via entry points. They were quite convenient throughout the development and testing, since they enabled variantlib to discover and query all the plugins installed in the development environment, without having to actually specify them in any way. However, it was pointed out that a more explicit and self-contained model would be preferable.
The next step was therefore to switch to a more explicit, opt-out design.
We added provider information to the variant information pipeline,
largely inspired by PEP 517, with a requires key specifying how to install
the variant provider, and a plugin-api key specifying how to use it.
Over time, we also added an enable-if key to support installing plugins
only in specific environments (for example, the x86_64 plugin is only needed
on x86-64 systems), and an optional key to make some plugins opt-in
(for example, for variants used only in obscure configurations that should
not be used by default). This also implied that the installer would now install
plugins automatically, using isolated environments.
With plugin installation and discovery taken care of, one major problem remains: variant sorting. Let's take a closer look at it next.
Variant sorting
Variant providers have two main purposes in aiding installers. First, they are used to filter variants, that is tell which of the wheels are supported. Second, they are used to sort compatible variants, ranking them from the most to the least desirable.
In the simplest cases, sorting is easy. If you have a bunch of variants
for different CPU baselines, you sort them from the highest to the lowest,
and therefore install the most optimized variant available. If you have variants
for different lower CUDA runtime bounds, you choose the one that is the highest;
say, if you have CUDA 12.8, you'd rather take a >=12.8,<13 wheel
than a >=12.6,<13 one, as it will likely have improved performance.
And if you have two wheels built for the same CUDA version, but one of them
also carries CPU optimizations, you'd take the latter.
The problems start when you have two different wheels that cannot be trivially compared; say, a CUDA-optimized wheel and a CPU-optimized wheel. You may have a gut feeling that CUDA wins, but this is not a general rule. Things become even harder when you have to choose between a CUDA and a ROCm wheel (say, on a machine with both an NVIDIA and an AMD GPU installed).
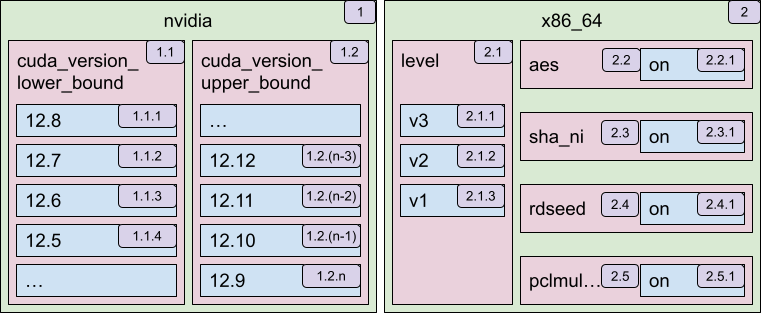
What we implemented is pretty much sorting on multiple layers. First, the supported values for every feature are sorted from the most preferred to the least preferred, so that a higher CUDA runtime version is considered better than a lower one, and a higher CPU architecture version likewise. Then, the features themselves are sorted within every namespace; e.g. indicating that a specific architecture version is more important than an individual feature, so you'd rather take an x86-64-v3 wheel with no additional instruction sets declared, over one declaring AVX support (which is already included in x86-64-v3) but using x86-64-v2 baseline. As a next step, namespaces are ordered, deciding whether CUDA, ROCm or perhaps CPU optimizations are more important. This way, we reach the point where every property has a corresponding sorting key, determined by its namespace, feature name and value ordering.
Let's return to our initial example and add sort keys to it.
nvidia :: cuda_version_lower_bound :: 12.6 // 1.1.3nvidia :: cuda_version_upper_bound :: 13 // 1.2.mx86_64 :: level :: v3 // 2.1.1x86_64 :: sha_ni :: on // 2.3.1
We sort variants according to the properties they have. While this may seem complex at first, it effectively follows a single rule: a variant having a more preferable property is better than one that does not have said property. And that's it!
Let's say we have three properties, most preferred to least preferred: P1, P2, P3. A variant having [P3] is better than variant having no properties at all, since it has P3 and the other does not. A variant [P2] is better than [P3], since it has P2 and the other does not. And [P2, P3] is better than all of the above since it has both these properties, and the others are missing at least one of them. And then [P1] is better than all of them, since they are missing the most preferred property; and so on, up to the [P1, P2, P3] variant that has all the possible properties, and is therefore the most desirable.
What does this imply in practice? Say, if the nvidia namespace is given higher
priority than the x86_64 namespace, then a CUDA variant will be preferred over
an x86-64-v3 variant, and a CUDA + x86-64-v3 variant will preferred over a plain
CUDA variant, provided both have matching CUDA properties. However,
a CUDA >=12.8 wheel will be preferred over a CUDA >=12.6 + x86-64-v3 wheel.
However, we believe that such mismatched combinations are unlikely to be published in reality.
Where do sort keys come from
I have explained how variants are sorted, using specific namespace, feature name and value ordering. However, what I didn't cover is how these bits are ordered themselves. To skip a bit ahead, we settled on a layout that uses three layers of sorting configuration:
- Sorting defined by the provider plugin itself.
- Sorting defined by the package (in variant information).
- Sorting defined by the user.
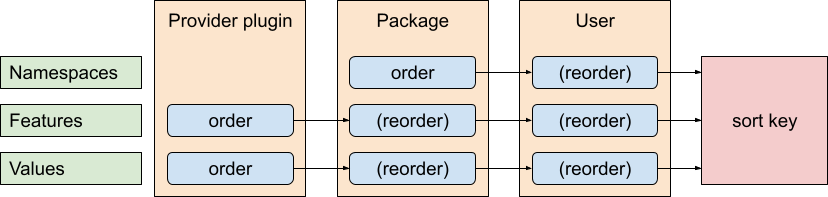
Unsurprisingly, plugins provide the initial ordering of features and their
values. After all, given that the plugin defines these lists in the first place,
it is quite reasonable for it to order them as well. Otherwise, the package
maintainers would have to keep repeating that 12.8 > 12.7 > 12.6 > …, and updating this
list whenever they are about to use a new property value.
However, plugins are scoped to themselves and can only order feature names
and values. They cannot provide namespace ordering, as that would effectively
mean one plugin deciding how important another plugin is.
[variant.default-priorities]# prefer aarch64 over x86_64namespace = ["aarch64", "x86_64"]# prefer variants using hardware AES optimizations over these for a newer CPU# architecturefeature.aarch64 = ["aes"]feature.x86_64 = ["aes"]# prefer x86-64-v3 and then older (even if the CPU is newer)property.x86_64.level = ["v3", "v2", "v1"][variant.providers.aarch64]# Using different package based on the Python versionrequires = ["provider-variant-aarch64 >=0.0.1,<1"]# use only on aarch64/arm machinesenable-if = "platform_machine == 'aarch64' or 'arm' in platform_machine"plugin-api = "provider_variant_aarch64.plugin:AArch64Plugin"[variant.providers.x86_64]requires = ["provider-variant-x86-64 >=0.0.1,<1"]# use only on x86_64 machinesenable-if = "platform_machine == 'x86_64' or platform_machine == 'AMD64'"plugin-api = "provider_variant_x86_64.plugin:X8664Plugin"
pyproject.toml with sort order definedThis left us with two possibilities: either the package author or the user needs to define namespace ordering. Originally, we went with the latter idea; after all, the users know best whether they prefer CUDA or ROCm, or perhaps CPU optimization. However, this meant that the user had to jump through the hoops of configuring variant usage first, and once again things could not work out of the box. So we went with the next best thing possible: requiring package maintainers to specify namespace ordering in the variant configuration; after all, package authors are in good position to specify which variants are the most beneficial to their software.
However, there was no reason to stop at namespace boundary. After all, a specific package may want to point out, say, that their AES-NI variant is more performant than a fallback implemented using the instruction sets provided by x86-64-v3. It might also be desirable reorder values; while I immediately can't think of a specific use case for that, we added the option for symmetry. This is how we arrived at the design presented in listing 4.
On top of that, there is still a valid use case for the user to override the sort order. Therefore, we permitted the initial configuration provided by the plugins and then altered by the package metadata to be further modified through user configuration. And since setting it is no longer obligatory, having the user configuration as an option is not a problem.
The null variant
Let's consider that you are distributing a package with three CUDA variants, and a CPU variant.
torch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu129.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu128.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu126.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64.whl // CPU-only
The setup presented in listing 5. provides for a graceful fallback. Depending on your exact CUDA version, the top variants can be filtered out, and the lower variants will be used instead. If you don't have a compatible CUDA runtime at all, the fallback CPU wheel is used. So far, so good.
However, consider a system with an older package manager version that does not support variants. Independently of the presence of CUDA runtime, all variant wheels are ignored there, and the CPU-only fallback is installed. However, this is not the most optimal solution. Prior to introducing variants, the published wheels may have featured both CUDA and CPU support (even if for a single CUDA version).
This is where the null variant comes in.
torch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu129.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu128.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-cu126.whltorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64-00000000.whl // CPU-onlytorch-2.8.0-cp313-cp313-manylinux_2_28_x86_64.whl // CUDA 12.6 + CPU
Consider the setup in listing 6. What we added here is a null variant, labeled
00000000 to make it easily distinguishable. It is built as a variant wheel,
but its variant property list is empty. It is always considered compatible with
the system (it has no unsupported properties), as long as variants
are supported in the first place. It always sorts after other variant wheels
(since every other variant has some property that makes it more preferable).
This enables us to provide two different fallbacks:
variant-enabled installers with no compatible CUDA runtime will use the CPU-only null
variant, whereas installers without variant support (and therefore unable
to determine the CUDA runtime version) will instead pick up the regular wheel, with both
CUDA 12.6 and CPU support.
Does it really matter? Well, that depends on how you look at it. Prior to wheel variant support being widely deployed, backwards compatibility is going to be important. And providing a different fallback may mean the difference between installing a 175 MiB CPU-only wheel, and a 850 MiB CUDA wheel, on a system without the CUDA runtime.
Multiple property values
So far, we have discussed wheels where every feature has a single value declared.
Say, a wheel that is optimized for a particular CPU architecture version,
or has one CUDA version lower bound and one upper bound. The key point here
is that for a variant to be compatible, all its features had to have a value
compatible with the system in question. This logic is conjunctive, that is representing
logical AND. You need to have a supported CPU, and a CUDA version that is
not older than the lower bound, and a CUDA version (the same one) that is older
than the upper bound.
CPU instruction sets are an interesting case. Each
instruction set is represented by a separate feature, with a single possible
value of on. If the user's CPU supports a given instruction set, it supports
said on value; if it doesn't, the feature has no compatible values. A wheel requiring
said instruction set includes this property with the on value.
And for the wheel to be compatible, all its features, that is all
listed instruction sets, need to be supported.
Now consider the opposite case: e.g., you are building a CUDA-enabled package
that supports multiple GPU series. You don't want to build a separate
wheel for every GPU; that would be a lot of wheels with significantly overlapping contents.
You want to build a single wheel and declare it compatible with multiple GPUs.
Conjunctive logic can't work here; you need disjunction, an OR.
Specifically for this use case, we introduced the ability to specify multiple values for the same feature, with the requirement that at least one value must be supported for the wheel to be compatible. Consider the property list in listing 7.
nvidia :: sm_arch :: 70_realnvidia :: sm_arch :: 75_realnvidia :: sm_arch :: 80_realnvidia :: sm_arch :: 86_realnvidia :: sm_arch :: 90_realnvidia :: sm_arch :: 100_realnvidia :: sm_arch :: 120_realnvidia :: sm_arch :: 120_virtual
It is the set of variant values for sm_arch you'd get when building PyTorch
with the build parameter from listing 8.
TORCH_CUDA_ARCH_LIST="7.0;7.5;8.0;8.6;9.0;10.0;12.0+PTX"
Note the reversal of semantics. Previously, the wheel declared what it required, and the plugin would indicate what the system provided. Here, we are seeing the exact opposite: the wheel declares what it supports, and the plugin declares what support is required by the system. Your system has some GPU and therefore it must be supported by the package. If it is on the list of supported architectures, the wheel is considered compatible; if it is not, the wheel is rejected.
Of course, this is far from providing an exhaustive boolean logic that could support all possible use cases. For example, you can't express that a wheel provides both CUDA and ROCm support, and that therefore is compatible with systems that have either CUDA or ROCm capability, but incompatible with systems without either. Nor can you express that your package uses two algorithms implemented using different combinations of instruction sets, but requires only one of them to be supported. However, our goal so far was to keep things simple whenever possible, and focus on the most probable use cases. And in the end, it is always possible (though not necessarily recommended) to create a dedicated provider plugin to cover the specific use case.
So, at this point, different features are conjunctive (all of them must be supported), but different values within a single feature are disjunctive (at least one of them must be supported).
Static and dynamic plugins
So far we have been assuming that the lists of allowed features and their
values are roughly fixed. A particular version of the x86_64 plugin implements
the properties for a certain range of architecture levels: say, v4 and lower.
We can't predict what v5 will be like, and a new plugin version will need
to be released to support it. However, this is not a significant issue,
as new architecture levels are introduced relatively rarely. Such a provider
is called a static plugin; one where the list of all valid property values
is supposed to remain the same within a single version, and therefore the list
of supported properties is independent of which packages are being installed.
Now let's consider a different use case: we need to express a dependency
on a runtime whose version changes frequently, and is not predictable.
Said version could be 1.0.0, 1.2.2, 2.0.10, 2.3.99… The runtime
in question does not use semantic versioning or another version scheme that clearly
indicates compatibility, so we may need to declare arbitrary version ranges.
We're facing
two problems here. First, the list of all valid values can be very long
(to be precise, infinitely long). Second, we can't fully predict what
the future versions will be.
Let's start with the lower bound. If the system has version 1.2.2 installed,
the plugin needs to declare compatibility with wheels that have a lower bound
no higher than that: >=1.2.2, >=1.2.1, >=1.2.0… but next, we'd need to list
all the possible 1.1.x versions, and should be the highest value of x
that we need to account for? And what if sometimes upstream
releases four-component versions, like 1.2.2.1? With upper bound, things
get even worse. Here we actually have to declare compatibility with versions
higher than the current version: <1.2.4, <1.2.5… ad infinitum.
Dynamic plugins were designed to address precisely this problem. The difference is that a dynamic plugin does not return a fixed list of all supported properties for a given machine, but rather directly determines which of the available wheel variants are compatible. This implies that there does not need to exist a fixed list of valid properties. Instead, the plugin can document a specific format for the property value, and process it algorithmically to determine its compatibility.
Let's revisit the version problem. The thing is: we don't have to predict
versions anymore! Instead, we document that the lower bound value
and the upper bound value both are version strings. When building the wheel,
the plugin verifies that valid version strings are passed. When installing
wheels, it parses the values as version strings and compares them
to the installed version. In fact, we can do even better: instead of separate
lower and upper bounds, we can have a single property that is a version
specifier, say, >=1.2.2,<3,!=1.7.4,!=1.8.1. This makes it both more flexible
and more readable.
Dynamic plugins can do all that static plugins can do, and more. Why do we need two plugin classes then? Why can't we just call it a day, say that we've found a better solution and go with it? The advantage of static plugins is that they are, well, static. Their behavior does not depend on the package being installed, they don't need to know what variants are available, and therefore their results can be cached and reused easily. You just run the plugin, snapshot the result and you can reuse it for any package you install.
This becomes especially important when we get around to discussing security. As I've mentioned earlier, querying a variant plugin effectively means installing packages and executing their code immediately. One clear way to circumvent this is to use a frozen plugin output instead of running the plugin locally. Say, you could snapshot the output from another environment with a compatible setup, or even create one manually.
However, this can only work if the output is either fixed or reasonably predictable. You can snapshot a limited length list of compatible CPU architecture versions, but you can't snapshot all possible version specifiers. With dynamic plugins, the best you can do is prepare the output for a predefined set of possible values (possibly grabbed from existing wheels) and recheck whenever you find new values.
In fact, this problem is considered significant enough that the nvidia provider plugin created for the demo was reverted to being a static plugin, with the possibility of creating a separate dynamic plugin if the need arises in the future, even though it means that it effectively guesses future versions of CUDA runtime! Fortunately, they are reasonably predictable.
By the way, while implementing the explicit distinction between static and dynamic plugins, we managed to keep the API differences absolutely minimal. In particular, both types of plugins use the same function signature:
def get_supported_configs( self, known_properties: frozenset[VariantProperty] | None) -> list[VariantFeatureConfig]: ...
The only difference is that static plugins take known_properties=None,
and return a fixed list, while dynamic plugins take the set of known property
values that is constructed from the available variants, and use them to construct the return value.
From the implementation's point-of-view, both types of plugins are handled
by the same code path, with the same sorting algorithms, differing only
in whether known_properties are passed or not.
Variant-specific dependencies
There are two dependency-related problems that could be relevant to variant support: expressing dependencies that are specific to a subset of variants, and requiring a specific variant (or a subset of variants) of another package. So far, we have deferred working on the latter problem, as we did not have a specific use case to focus the design on, and we did not want to arrive at a complex solution that would not necessarily match what the users actually needed. On the other hand, variant-specific dependencies had immediate use cases.
The idea of variant-specific dependencies arrived into the project quite early.
After all, building a variant wheel generally involves installing a provider
plugin, if only to validate whether the requested properties are correct.
And indeed, the very first attempt to do that used environment markers
in the build-system.requires section of pyproject.toml, to specify which
plugins needed to be installed. It looked somewhat like the snippet in listing 9.
[build-system]build-backend = "mesonpy"requires = [ "meson-python", "provider-variant-x86-64; 'x86_64' in variant_namespaces", "provider-variant-aarch64; 'aarch64' in variant_namespaces",]
pyproject.toml with variant provider plugins selected via environment markersThese markers meant that when the variant wheel was built with a property in the listed namespace, the relevant provider plugin was installed in the build environment, and therefore became available to the build backend. However, this solution did not last long. It was quite problematic to implement given the limited interface between pypa/build and the installers used by it. Besides, provider plugins also needed to be installed while installing variant wheels, so it made more sense to separate them, as described earlier in the post.
Nevertheless, the syntax based on environment markers made sense, and it eventually made its way into the actual package dependencies. A package that previously had to dynamically declare different dependency sets for every wheel variant, now could instead use them to apply dependencies conditionally to the selected variant.
dependencies = [ 'triton==3.4.0; platform_system == "Linux" and "nvidia" in variant_namespaces', 'nvidia-cudnn==9.10.2.21; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia" in variant_namespaces', 'nvidia-cusparselt==0.7.1; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia" in variant_namespaces', 'nvidia-nccl==2.27.3; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia" in variant_namespaces', # CUDA 12.6 builds are used for >=12.0 'nvidia-cuda-nvrtc==12.6.77; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.0" in variant_properties', 'nvidia-cuda-runtime==12.6.77; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.0" in variant_properties', # CUDA 12.8 builds are used for >=12.8 (will be preferred over >=12.0) 'nvidia-cuda-nvrtc==12.8.93; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.8" in variant_properties', 'nvidia-cuda-runtime==12.8.90; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.8" in variant_properties', # CUDA 12.9 builda are used for >=12.9 (will be preferred over >=12.8) 'nvidia-cuda-nvrtc==12.9.86; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.9" in variant_properties', 'nvidia-cuda-runtime==12.9.79; platform_system == "Linux" and platform_machine == "x86_64" and "nvidia :: cuda_version_lower_bound :: 12.9" in variant_properties',]
pyproject.toml dependency string with variant-based environment markersThere are three environment markers available: variant_properties
corresponding to the set of the variant properties that the wheel was built for,
variant_features combining them into enabled features (i.e. features that have
at least one value), and variant_namespaces doing the same for namespaces.
There has also been a discussion of adding a marker to match variant label
specifically, i.e. variant == "cu129", but so far there did not seem
to emerge a really good use case for it, and it was deemed unnecessarily risky,
as building the same variant with a different label would cause the dependency
to stop applying.
The discussion around environment markers surfaced more interesting problems.
For a start, it was pointed out that there could be two different types
of markers: markers matching the properties of the installed wheel (as outlined
previously), and markers matching the current system state. For example,
the latter could be used to install the nvidia plugin if CUDA is available without
actually having to publish a separate CUDA variant of the main package (think
JAX). However, this is a recent development and it has not been pursued yet.
It was also pointed out that these kind of dependency specifiers can create
potential conflicts. For example, since technically a wheel can have multiple
values for a property, the code in listing 10. could end up pulling in two or three versions
of nvidia-cuda-runtime simultaneously. We are still working on some
of the finer implications of that, such as how it affects the creation
of universal lockfiles, that attempt to account for all valid environment
marker combinations.
Let's talk about security
The most important part of the design that we're still working on is security. The installer, including all its (possibly vendored) dependencies, is sometimes found operating with elevated privileges, for example when it is used to install packages for all users, on a multi-user system. Variant provider plugins will be operating with the same level of privileges, and this has significant implications on how they are developed.
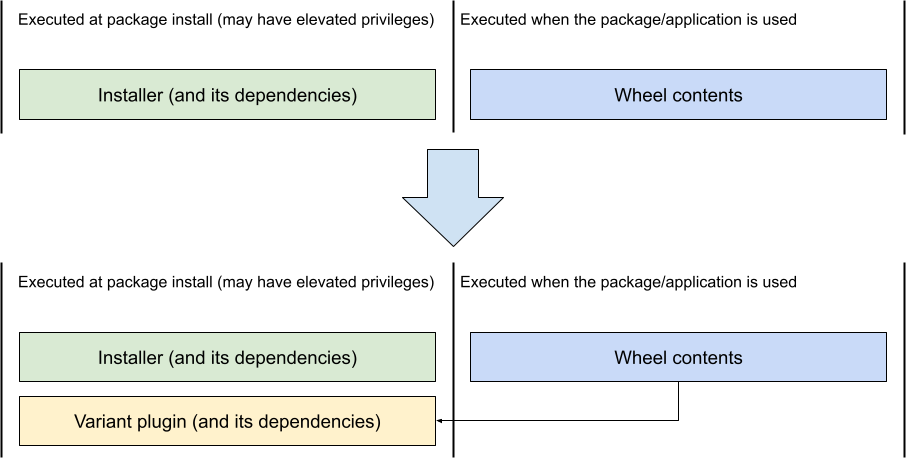
There are two main risks being considered here. First, malicious code could be introduced into an existing variant provider or one of its dependencies; this is a similar risk to how such code could be introduced in the installer itself. Second, a new provider could be created that includes malicious code by design, and existing packages could start using it.
It can be noted that these risks are similar to those for build backends,
which are also downloaded dynamically during the install process and execute
arbitrary code throughout the build. However, this risk does not apply
to installing from wheels, and can be mitigated in environment with higher
security expectations by disabling source builds, e.g. via pip install --only-binary :all:.
Similarly, there are multiple ways in which the risks from using variant wheels could be mitigated. I have already mentioned the possibility of using frozen variant provider output instead of running the plugin locally. However, this requires additional effort from the user and will primarily be used in setups with high security requirements.
To avoid indirect supply chain attacks, variant providers could recursively pin or vendor their dependencies. The latter option is especially interesting, since it can be easily enforced at installer level, by forcing provider plugins to be installed without dependencies. This way, we mitigate the risk of a new version of a compromised dependency being immediately deployed to end users. This should not be a major maintenance burden, given that we expect most variant providers to be small and have few or no dependencies.
Technically, attack surface could be further reduced by pinning variant providers to specific versions. However, this is unlikely to be a good idea, since it implies that the wheels for previous package versions would be forever pinned to old versions of plugin providers, making it impossible to benefit from bug fixes and updates (say, new CPU could fail to be recognized as compatible with an old variant).
One interesting option is to maintain a central registry of vetted plugin providers. Since such a registry can be updated independently of existing wheels, it can mitigate the risk of a provider being compromised without actually permanently pinning to old versions of packages. Unfortunately, the primary problem with such a solution lies in establishing such an authority, and ensuring that it remains reliable in the future. It also introduces a single point of failure.
Installers could execute provider plugin code in a sandboxed environment,
with lowered privileges and limited system access. However, such restrictions
will need to be carefully assessed, in order to avoid restricting the plugin's
functionality. For example, the nvidia plugin needs to be able to access
the installed NVIDIA libraries and query the GPU.
The more popular provider plugins can also be vendored or reimplemented by installers themselves, therefore avoiding reliance on third-party sources. However, it means that the installer maintainers will have to keep track of the plugin development, and users cannot benefit from bug fixes and improvements without updating the installer.
Finally, there is always the possibility of providing better control over variant use. For example, the installers could request an explicit confirmation before running a provider plugin for the first time (the trust-on-first-use paradigm), permit users to manually select variants or disable variant use entirely. After all, a user who does not use an NVIDIA GPU does not really need to query the respective plugin.
We're confident that this will result in something that will be acceptable to the community after the design and its review are fully complete.
The present, and the future
In this post, I've attempted to comment on the road taken by the variant wheel work, from the project's inception to the current state of the pre-proto-PEP: PEP ### - Wheel Variants. Necessarily, this story is neither final nor covers all the details, but I think it does some justice to the complexity of the problem space and the effort put into developing a good solution.
Overall, we have been following the philosophy of the WheelNext initiative, and focusing on providing a working solution to real-world problems. I believe that this approach worked well, and we arrived at a proposal that does not introduce more complexity than absolutely necessary, to solve the problems we were facing, and attempts to use generic solutions whenever possible. More than once through the process, it turned out that a single past decision either provided a ready solution to the future problems that we did not originally anticipate, or made it possible with minimal changes to the design.
We started with a simple conjunctive property framework, managed to easily
handle flag-like properties with it, and then extended it to handle multiple
values disjunctively, therefore solving the GPU target problem with minimal changes
to the specification. We introduced variants.json to solve an immediate
scalability problem, yet it enabled us to easily introduce custom variant labels
later on. We created a relatively simple and clean API, and were able
to extend it to support dynamic plugins without changing much. And the sort
algorithm that was originally devised for the one-value-per-property design,
required no changes when we introduced multi-value properties and the null
variant.
Of course, the work is far from complete. We have solved a number of problems, we have arrived at a working prototype; but as more people start testing it against their own packages, and as more people join the discussion, new use cases and new problems will emerge. This does not necessarily mean that we will have to go back to the proverbial drawing board. It is entirely possible that the existing framework will suffice for many of these issues, much like we eventually managed to implement a good enough plugin for CUDA without having to make it dynamic; or that they will turn out not to be worth the added complexity. It is also possible that some of the existing features will be removed.
There are open issues still. There's the question of how lockfiles are supposed to work with variants. There's the possible matter of dependencies on specific variants. But most importantly, we are working hard to resolve all concerns regarding the security of variant provider plugins. Yet, variant wheels are a good solution to a problem that at least part of the Python community has been facing for many years, and we are looking forward to see them deployed.
Acknowledgements
Many people have been involved in the wheel variant design to date. I'd like to thank Jonathan Dekhtiar (NVIDIA), Konstantin Schütze (Astral), Charlie Marsh (Astral) and my colleague Ralf Gommers, in particular. Thanks to Eli Urieges (Meta) and Andrew Talman (Meta) for supporting and preparing the PyTorch 2.8.0 release with experimental support for wheel variants that is available today.
Thanks to Red Hat for funding Quansight's contributions to the wheel variant design. Red Hat is shipping accelerator-enabled Python packages, like PyTorch, as wheels in a virtual environment as part of Red Hat AI, and saw the importance of improving Python packaging for heterogeneous hardware, resulting in their support for the WheelNext initiative.

