

Python packaging & workflows - where to next?
Published January 10, 2023


rgommers
Ralf Gommers
A lot is going on in Python packaging land. Two weeks ago I released the pypackaging-native website, which documents extensively what the most important issues are with packaging Python projects that contain code that needs to be compiled. It's something I had wanted to have for a long time, and I sincerely hope that it'll help improve the quality of Python packaging design discussion. Right before that release, there was a large discussion on Discourse - Wanting a singular packaging tool/vision - about future wishes and big picture packaging topics/changes. A second big picture thread, Python Packaging Strategy Discussion - Part 1 is active right now (and the title implies there'll at least be a "strategy - part 2" one).
pypackaging-native content on purpose does not go into detail on solution
directions. Real-world problems are, well, real. Unlike for new ideas, it's
hard to argue with concrete examples of "this doesn't work for me or my
project, because of X". While for preferred solution directions, one can be a
lot more opinionated. And one person's solution may be another's unwanted extra
thing to worry about.
This blog post is my attempt to address solutions, and what I hope is a good way forward for Python packaging as a whole.
The short version
This is going to be a long post, so for the impatient reader here are the key points. The most important design changes for Python packaging to address native code issues are:
- Allow declaring external dependencies in a complete enough fashion in
pyproject.toml: compilers, external libraries, virtual dependencies. - Split the three purposes of PyPI: installers (Pip in particular) must not install from source by default, and must avoid mixing from source and binary features in general. PyPI itself should allow uploading sdist's for redistribution only rather than intended for direct end user use.
- Implement a new mode for installers: only pure Python (or
-any) packages from PyPI, and everything else from a system package manager. - To enable both (1) and (3): name mapping from canonical PyPI names to other names.
- Implement post-release metadata editing capabilities for PyPI.
Equally important, here are the non-changes and assumptions:
- Users are not, and don't want to become, system integrators,
- One way of building packages for everything for all Python users is not feasible,
- Major backwards compatibility breaks will be too painful and hard to pull off, and hence should be avoided,
- Don't add GPU or SIMD wheel tags,
- Accept that some of the hardest cases (complex C++ dependencies, hairy native dependencies like in the geospatial stack) are not a good fit for PyPI's social model and require a package manager which builds everything in a coherent fashion,
- No conda-abi wheels on PyPI, or any other such mixed model.
On the topic of what needs to be unified:
-
Aim for uniform concepts (e.g., build backend, environment manager, installer) and a multitude of implementations,
-
Align the UX between implementations of the same concept to the extent possible,
-
Build a single layered workflow tool on top (à la Cargo) that,
- allows dropping down into the underlying tools as needed,
- is independent of the tools, including what package and environment managers to use. Importantly, it should handle working with wheels, conda packages, and other packaging formats/systems that provide the needed concepts and tools.
For rationales for and more details on these points, read on!
The long version
Let me start with the key assumptions I'm making, because they're important for everything else. The first is "users are not, and don't want to become, system integrators". To maintainers of scientific/PyData packages, this is 100% obvious. If you're working in, say, DevOps or web development where (a) almost everyone is a developer, and (b) most things are pure Python, so there is less integration to do, it may not be though. Let me quote Steve Dower, who explicitly asked the question "should we be trying to make each Python user be their own system integrator, supporting the existing integrators, or become the sole integrator ourselves?":
One concrete example that some of us have been throwing around for years: the difference between an “system integrator” and an “end user”. That is, the person who chooses the set of package versions and assembles an environment, and the person who runs the Python command. They don’t have to be the same person, and they’re pretty clearly totally distinct jobs, but we always seem to act as if end users must act like system integrators (i.e. know how to install compilers, define constraints, resolve conflicts, execute shell commands) whether they want to or not.
This is all correct, the average user doesn't want to do any of those things and gets very confused very quickly if it is required. Hence supporting the existing integrators better is pretty clearly the right way forward.
The second assumption is: one way of building packages for everything for all Python users is not feasible. This should be self-evident - Python is one of the most diverse languages in terms of application domains and types of users. HPC users are going to continue to want the capabilities of Spack (or something like it), scientific and data science users are going to continue to like a full-featured binary packaging system like Conda, DevOps users are going to continue to want the flexibility of PyPI/wheels/pip, and there'll continue to be more flavors for other use cases and personal tastes.
The last main assumption is: major backwards compatibility breaks will be too painful and hard to pull off. This is simply based on previous experience with packaging changes and the level of coordination and effort needed for any major breaks. I'm thinking about things like "change conda so it works with wheels and non-conda Python installers". Or "stop distributing standalone Python installers on python.org". It's not impossible, however such proposals are unlikely to succeed.
The way forward for native code
The single biggest issue for dealing with C/C++/Fortran/CUDA/etc. code is
native dependencies (i.e., depending on libraries written in those non-Python
languages and not present on PyPI), as discussed on
this set of pypackaging-native pages.
The initial hurdle there is not that those dependencies are not on PyPI, but
that we cannot even express the external dependencies a package has.
The solution seems obvious (the devil will be in the details probably though):
allow declaring external dependencies. This has to be done in a complete
enough fashion, so dependencies on compilers, external libraries (whether from
another specific packaging ecosystem or independent of that), and virtual
dependencies (i.e., dependencies that can have multiple providers) can all be
declared. That metadata should live in pyproject.toml. It's going to be a
nontrivial amount of work and require a PEP to work this out. The
implementation may use something like
namespaces,
or purl, or something in a similar
direction but custom to Python. Either way, it's a universal scheme and/or some
form of mapping from canonical PyPI names to other names.
A second change that is very much necessary is to better split the three purposes of PyPI (see this explanation). This is primarily a conceptual and package installers issue. Installers, Pip in particular, must not install from source by default, and must avoid mixing from source and binary features in general. There are very few packaging systems that do mix building from source and serving binaries, and for those that do the binary serving really acts like a cache. For Pip that's not true - building from source almost certainly results in a very different wheel than the one with the same tags that's up on PyPI. The primary thing to work on is pip#9140; other installers should mirror that change, and in addition there are secondary things to do, like disabling caching of locally built wheels. On PyPI itself it should probably also become possible to allow uploading sdist's for redistribution only rather than intended for direct end user use. This can be done with some kind of tagging, or a separate upload API. It will remove the incentive for projects to upload wheels without a matching sdist. This set of changes will actually not be all that much work, at least compared to most of the other design changes proposed in this post.
A third change to make is to implement post-release metadata editing capabilities for PyPI. This has been discussed on and off for a long time. It is needed for multiple reasons, discussed on this pypackaging-native page. Almost any system package manager as well as conda-forge and Spack can do this, and it has significant benefits. A particular one to highlight is upper bounds on dependencies: we can then stop worrying about (and fighting over) those. Upper bounds are about "what happens in the future", and no one has a crystal ball. The ability to fix breakage easily when it occurs is invaluable. I'll also highlight that Poetry - overall a very polished and popular project manager - gets a lot of flak exactly for adding upper bounds by default. This is, in my opinion, unfair. Poetry does have valid reason to do what it does - see its FAQ entry on the topic. Overall the downsides are probably larger than the upsides, but really there are only two pretty bad choices right now to deal with version constraints, and no good ones. Making metadata editable removes the conundrum.
These design changes are quite a lot of work already - but still modest compared to other proposals that have been thrown around, and probably all feasible to execute on. Let me also add a few potential design changes that I'd suggest to avoid making - less work!
Out of scope
Distributing packages with GPU code or SIMD code on PyPI is very challenging, as discussed here and here respectively. However, I'm still going to recommend against adding GPU or SIMD wheel tags. Adding such tags would be a large amount of work, and in and of itself not really be a solution. The current state is somewhat acceptable. In the case of SIMD code it can be further improved by making it easier to implement runtime CPU architecture detection and dynamic dispatch - this is a capability that build systems (e.g., Meson and CMake) can support, and reusable libraries can facilitate. For GPUs it would not solve the binary size issue; solid GPU support is probably best left to system package managers.
Another thing that I'd propose to do is to accept that some of the hardest cases (complex C++ dependencies, hairy native dependencies like in the geospatial stack) are not a good fit for PyPI's social model and require a package manager which builds everything in a coherent fashion. Very complex builds and dependencies across a larger set of native libraries simply need a coordinated approach. The strength (or weakness, depending on your point of view) of PyPI is that every package author can and will do their own thing, at their own time. That is a pretty fundamental property of how the PyPI ecosystem works, and isn't going to change. Hence it's best to accept that, avoid the huge amount of effort to produce working sets of wheels for the most complex builds, and instead make all of Python packaging work better together with system package managers where doing those complex builds is a lot easier and can be done by specialists rather than package authors.
Supporting system integrators - a new installer mode
What we discussed so far will be a lot of work - but they're all logical and
previously-discussed ideas, and don't yet answer the question: if we want to
better support system integrators, then how do we do that?
The answer I'll propose here has, to the best of my knowledge, not been
discussed seriously before. That answer is: implement a new, opt-in mode for
installers, only pure Python (or -any) packages from PyPI, and everything
else from a system package manager.
Such a new installer mode has a number of nice properties:
- No significant backwards compatibility issues, because it's opt-in by end users.
- It's the one clean split one can make between what's on PyPI and what comes from another package manager without running into ABI issues.
- With the external dependencies specification, package name mapping and this install mode, it will be possible to declare and fulfill all dependencies.
- Widely used packages that are still reasonable to build as wheels (e.g., the likes of NumPy, SciPy and scikit-learn) can continue their current release practices unchanged, while packages that are even harder to build or less actively maintained can opt out of the additional extra burden imposed by wheel building.
- Users that are happy with PyPI as-is don't have to change a thing, and are unlikely to be affected by the hardest to build packages no longer providing wheels.
- Packagers for other package managers can stop repackaging many pure Python packages if they want - they instead have the option to rely on PyPI.
That all sounds great ... but of course there's no free lunch. Here are some things that come to mind which we'd have to implement, on top of the design changes listed in the previous section:
- A way for other package managers to make themselves known to installers that are currently wheel/sdist-only,
- Sequential or joint dependency resolution over the two packaging ecosystems. This is the trickiest part. Note though that the non-PyPI package manager should be self-contained and won't rely on PyPI packages, so there's no back and forth there,
- UX for users to opt in to this installer mode, and associated diagnostics,
- Making the relevant tooling that makes use of dependency and installed package metadata understand the new install mode,
- ... and probably a few more things I didn't think about.
And of course, for every design change there's documentation and educational materials to update.
Python packaging strategy - what to unify?
So say that we're good on dealing with native code and better supporting system integrators. What's left then is the discussion on what to unify.
Let's start by referencing Nathaniel Smith's
excellent post on workflow tooling (2018),
which goes through various workflows Python users have. And introduces the
packaging elephant, and a single hypothetical workflow tool called pyp. It
expresses a lot of good ideas and workflows and constraints to think about, and
is still relevant after 4+ years. It's a tool like pyp, or cargo (the Rust
workflow tool), that we seem to want1. That should be a top-level tool that
wraps underlying tools, and is properly layered so that users can dig in and
both understand what's under the hood and reach down to that next more complex
level if they have to. The latter in order to use a tool directly if the
higher-level UX isn't sufficient, or to replace the underlying tool with a
similar one more suitable for their needs.
Pradyun Gedam asked the question what needs to be unified. I'll give that list (extended with one suggestion in a reply) and my yes/no on unification:
- Unification of PyPI/conda models -> NO
- Unification of the consumer-facing tooling -> NO
- Unification of the publisher-facing tooling -> NO
- Unification of the workflow setups/tooling -> YES
- Unification/Consistency in the deployment processes -> NO
- Unification/Consistency in “Python” installation/management experience -> NO
- Unification of the interface of tools -> YES (as much as possible)
For each NO, it seems either infeasible or not a good idea to really merge different tools. We have multiple tools for each job for a reason, and that's a good (or at least necessary) thing. As long as the tools that do the same job are mostly interchangeable, this is not a problem. We then have some reasonable default tool, and alternatives that can be plugged in. Interchangeable here means two things: the job or concept is well-defined, and the UX for the tool is either the same or close enough that the differences can be bridged.
This is perhaps a little abstract, so let's have a look at one type of tool - a
build frontend. There aren't that many build frontends, the two most popular
ones are pip and pypa/build. Their main job is to allow invoking a build
backend and build a wheel (pip may then install it too). The interfaces for
these two tools won't be the same, but interface alignment can happen to make
using them interchangeably easier. For example, here are some unnecessary
differences that the maintainers can align on:
--config-settings:buildallows a-Cone-letter abbreviation,pipdoes not--config-settings:buildallows duplicate keys,pipdoes not,- disabling build isolation:
pipuses--no-build-isolation,builduses--no-isolation, - dependency checking:
buildchecks by default (even with--no-isolation, which you often tend to use exactly when you want to deviate from dependencies/versions inpyproject.toml), whilepipdoes not. Flags are named differently:--skip-dependency-checkforbuild,--check-build-dependenciesforpip, - produced wheel location:
pip wheelputs it in the current directory by default and allows changing that with--wheel-dir,buildputs it indist/and allows changing that with--outdir.
A second set of tools are environment managers. These are fairly uniform, and
only have a few relevant concepts: an environment is something that can be
created, activated and deactivated, and that packages can be installed into.
Most tools have those concepts, with a similar UX. E.g., tool activate <envname> and tool deactivate <envname> are the same across venv,
virtualenv, conda/mamba and spack. Creating and removing environments
has some more variation. However, as long as the concepts are the same, it's
not too bad that the exact UX is different. At least it allows a higher level
tool to paper over the naming differences and wrap the lower-level tools in
order to provide a uniform experience for its users.
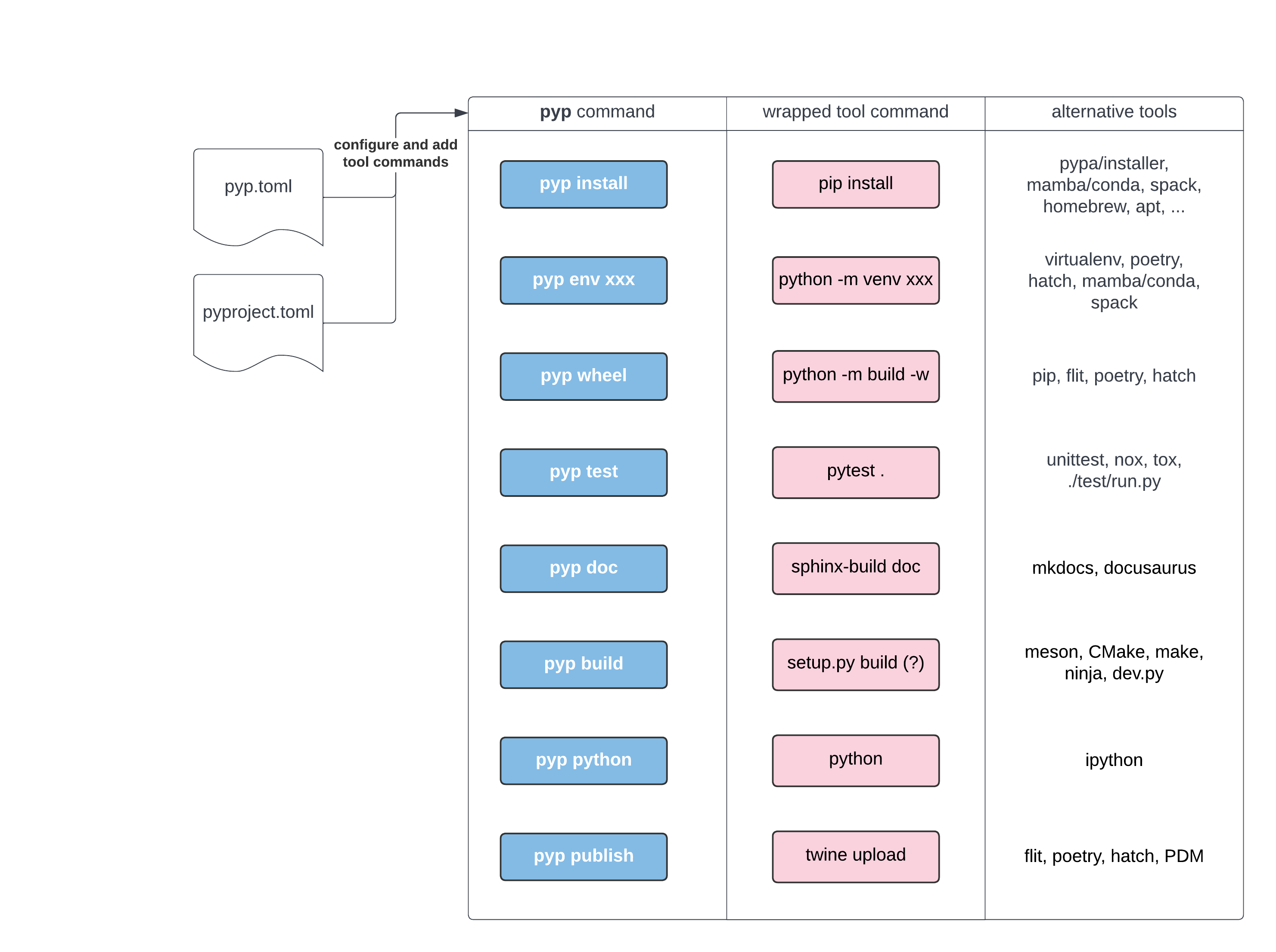
A sketch of a unified workflow tool, which wraps package managers,
installers, build frontends/backends, test/doc/benchmark development
tooling.
Wheh, thank you for reading to the end! I hope this looks like a way forward that either seems compelling or stimulates even better ideas.
Given that this is my very-ambitious-but-still-somewhat-realistic wish list, I can't resist adding one more wish: I want a documented design of Python packaging. Packaging PEPs are not a documented design. They're like a collection of random git commits for a project where you can't see the current state of the contents of the repository. I'd like to see that current state in written form.
Footnotes
-
I'll also note that SciPy, probably like quite a few other projects, has a custom developer CLI. That CLI is layered, it exhibits most of the properties that I talk about in this post, and is a pleasure to work with. ↩

