Making GPUs accessible to the PyData Ecosystem via the Array API Standard.
Published March 31, 2022


aktech
Amit Kumar
GPUs have become an essential part of the scientific computing stack and with the advancement in the technology around GPUs and the ease of accessing a GPU in the cloud or on-prem, it is in the best interest of the PyData community to spend time and effort to make GPUs accessible for the users of PyData libraries. A typical user in the PyData ecosystem is quite familiar with the APIs of libraries like SciPy, scikit-learn, and scikit-image -- and at the moment these libraries are largely limited to single-threaded operations on CPU (there are exceptions to that, like linear algebra functions and scikit-learn functionality which uses OpenMP under the hood). In this blog post I will talk about how we can use the Python Array API Standard with the fundamental libraries in the PyData ecosystem along with CuPy for making GPUs accessible to the users of these libraries. With the introduction of that standard by the Consortium for Python Data API Standards and its adoption mechanism in NEP 47 it is now possible to write code that is portable between NumPy and other array/tensor libraries that adopt the Array API Standard. We will also discuss the workflow and challenges for actually achieving such portability.
Motivation and goal
The motivation for this exercise comes from the fact that having GPU-specific code in SciPy and scikits will be too-specialized and very hard to maintain. The goal of this demo is to (a) to show things working on GPUs in a real-world code example using SciPy, scikit-learn and scikit-image together, and (b) demonstrate that there is a significant performance benefit. We'll be using CuPy as the GPU library for this demo. Since CuPy has support for NVIDIA GPUs as well as AMD’s ROCm GPU platform, this demo will work on either of those GPUs.
The ultimate goal is to have SciPy, scikit-learn and scikit-image accept any type of array, so they can work with CuPy, PyTorch, JAX, Dask and other libraries. This work is part of a larger project sponsored by AMD for extensibility to GPU & distributed support for SciPy, scikit-learn, scikit-image and beyond.
A primer on the Array API Standard
As of today, NumPy with over 100 million monthly downloads (combined from conda and PyPI) is the fundamental library of choice for array computing. In the past decade a plethora of array libraries have evolved, which more or less derives from NumPy’s API and its API is not very well defined. This is due to the fact that NumPy is a CPU-only library and today these dependent libraries are built for a variety of exotic hardware. As a consequence the APIs of these libraries have diverged a lot, So much so that it’s quite difficult to write code that works with multiple (or all) of these libraries. The Array API standard aims to address this issue, by specifying an API for the most common ways arrays are constructed and used. At the time of writing this, NumPy (>=1.22.0) and CuPy (>=10.0.0) have adopted the Array API Standard.
Note about using the Array API Standard
The definition of the Array API Standard and its usage may evolve over time. This blog post is only meant to illustrate how we can use it to make GPUs accessible to users of libraries like SciPy and scikits and the performance benefits of that. It does not necessarily define any best practices around adopting the standard. Such adoption best practices are still a work in progress and will evolve over the next year.
The example: image segmentation through spectral clustering
The example we have chosen to demonstrate adopting the Array API standard to make GPUs accessible in SciPy and scikits is the one taken from scikit-learn’s documentation: segmenting a picture of Greek coins into regions. This example uses spectral clustering on a graph created from voxel-to-voxel difference on an image to break this image into multiple partly-homogeneous regions (or clusters). In essence spectral clustering is about finding the clusters in a graph, i.e., finding the mostly connected subgraph and thereby identifying clusters. Alternatively, it can be described as finding subgraphs having a maximum number of within-cluster connections and a minimum number of between-cluster connections.

Greek coins from Pompeii ("British Museum, London, England").
Source: www.brooklynmuseum.org/opencollection/archives/image/51611
The dataset we are using for this demonstration is of greek coins from Pompeii
(from the skimage.data.coins module). This is a data of image of several
coins outlined against a gray background.
We convert the data of the coins into a graph object and then apply spectral clustering to it for segmenting coins.
The process for making the code run on GPU
get_namespace - getting the array API module
NEP 47, "Adopting the array API standard", outlines a basic workflow for adopting the array API standard for array provider and consumer libraries. Now we will describe in detail about how we went through the process of implementing this in forks of SciPy, scikit-learn and scikit-image.
The Array API defines a method named __array_namespace__ which returns
the array API module with all the array API functions accessible from it.
It has a couple of key benefits:
- for the array consumer libraries to be able to check if the incoming array supports the standard.
- to access all the functions that work with the array object without having the need to import the Python module explicitly.
NEP 47 recommends defining a utility function named get_namespace to check
for such an attribute.
An example of potential implementation of get_namespace function is defined as follows:
import numpy as npdef get_namespace(*xs): # `xs` contains one or more arrays, or possibly Python # scalars (accepting those is a matter of taste, but # doesn't seem unreasonable). namespaces = { x.__array_namespace__() if hasattr(x, '__array_namespace__') else None for x in xs if not isinstance(x, (bool, int, float, complex)) } if not namespaces: # one could special-case np.ndarray above or use np.asarray here # if older numpy versions need to be supported. raise ValueError("Unrecognized array input") if len(namespaces) != 1: raise ValueError(f"Multiple namespaces for array " "inputs: {namespaces}") xp, = namespaces if xp is None: # Use numpy as default return np, False return xp, True
Workflow - for using get_namespace
Now let's walk through an example to see how this works in practice. Consider the following function from SciPy:
def getdata(obj, dtype=None, copy=False): """ This is a wrapper of `np.array(obj, dtype=dtype, copy=copy)` that will generate a warning if the result is an object array. """ data = np.array(obj, dtype=dtype, copy=copy) # Defer to getdtype for checking that the dtype is OK. # This is called for the validation only; we don't need # the return value. getdtype(data.dtype)
This function is taken from scipy/sparse/_sputils.py. We can see that this
function explicitly calls np.array on the given array object: obj, without
realising the type of obj. This implementation is obviously not generic to
support any array library other than NumPy. We'll now apply the Array API's
get_namespace magic to make it generic, by adding a couple of lines to the code above:
def getdata(obj, dtype=None, copy=None): """ This is a wrapper of `np.array(obj, dtype=dtype, copy=copy)` that will generate a warning if the result is an object array. """ xp, _ = get_namespace(obj) data = xp.asarray(obj, dtype=dtype, copy=copy) # Defer to getdtype for checking that the dtype is OK. # This is called for the validation only; we don't need # the return value. getdtype(data.dtype)
Now you can see that get_namespace finds the Array API standard-compatible
namespace for the given object and calls .asarray on it instead of
np.array. Hence making it generic for any array provider library that
supports the standard.
 Workflow for using the Array API Standard for writing code that works with multiple libraries
Workflow for using the Array API Standard for writing code that works with multiple libraries
Applying it to our demo example
Now let's take a look at the code for our demo example (segmentation of the picture of greek coins in regions) to understand what it takes to make it run on GPU(s).
# Author: Gael Varoquaux <gael.varoquaux@normalesup.org>, Brian Cheung# License: BSD 3 clauseimport timeimport numpy as npfrom scipy.ndimage.filters import gaussian_filterimport matplotlib.pyplot as pltimport skimagefrom skimage.data import coinsfrom skimage.transform import rescalefrom sklearn.feature_extraction import imagefrom sklearn.cluster import spectral_clusteringfrom sklearn.utils.fixes import parse_version# these were introduced in skimage-0.14if parse_version(skimage.__version__) >= parse_version("0.14"): rescale_params = {"anti_aliasing": False, "multichannel": False}else: rescale_params = {}# 1. load the coins as a numpy arrayorig_coins = coins()# 2. Resize it to 20% of the original size to speed up the processing# Applying a Gaussian filter for smoothing prior to down-scaling# reduces aliasing artifacts.smoothened_coins = gaussian_filter(orig_coins, sigma=2)rescaled_coins = rescale(smoothened_coins, 0.2, mode="reflect", **rescale_params)# 3. Convert the image into a graph with the value of the gradient on the# edges.graph = image.img_to_graph(rescaled_coins)# Take a decreasing function of the gradient: an exponential# The smaller beta is, the more independent the segmentation is of the# actual image. For beta=1, the segmentation is close to a voronoibeta = 10eps = 1e-6graph.data = np.exp(-beta * graph.data / graph.data.std()) + eps# Apply spectral clustering (this step goes much faster if you have pyamg# installed)N_REGIONS = 25for assign_labels in ("kmeans", "discretize"): t0 = time.time() # 4. Apply spectral clustering on the graph (via `discretize` labelling). labels = spectral_clustering( graph, n_clusters=N_REGIONS, assign_labels=assign_labels, random_state=42 ) t1 = time.time() labels = labels.reshape(rescaled_coins.shape) # 5. Plot the resulting clustering plt.figure(figsize=(5, 5)) plt.imshow(rescaled_coins, cmap=plt.cm.gray) for l in range(N_REGIONS): plt.contour(labels == l, colors=[plt.cm.nipy_spectral(l / float(N_REGIONS))]) plt.xticks(()) plt.yticks(()) title = "Spectral clustering: %s, %.2fs" % (assign_labels, (t1 - t0)) print(title) plt.title(title)plt.show()
Let's walk through the code above to get a sense of what we're trying to achieve here.
- We have a dataset of Greek coins from Pompeii (imported from
skimage.data.coins) - We rescale the image to 20% to speed up processing
- Convert the image to a graph data structure
- Apply spectral clustering on the graph (via
discretizelabelling). - Plot the resulting clustering
Now to make it run on GPU we need to make minor changes to this demo code (as well as to each of the libraries involved - see the next section). We need to use a different array input for a GPU array. Since NumPy is a CPU only library we'll use CuPy, which is a NumPy/SciPy-compatible array library for GPU-accelerated computing with Python. In addition, we made the rescaling factor variable to be able to perform performance benchmarking as a function of input data size.
Changes to SciPy, scikit-learn, scikit-image, and CuPy
Since SciPy, scikit-learn, scikit-image are designed mainly for NumPy, we need
to use the Array API standard to dispatch to CuPy or NumPy based on the input.
We do that by changing all the functions that are called in the above demo to
use get_namespace, and to replace all the instances of np. (or numpy.) to
properly dispatch to the appropriate array library. This is straightforward
in some places, and not so trivial in others. We'll discuss the more
challenging cases in the next section.
The final code for the demo can be seen here.
The changes to SciPy, scikit-learn, scikit-image and CuPy can be seen here:
The notebook for the demo can be seen here.
Challenges and workarounds
At the moment the Array API standard specifies a lot of the most commonly used functions in the NumPy API. This makes it easier to replace NumPy functions with equivalent ones in the standard. There are still some rough edges though, which makes the process a bit harder. These are the three main issues we faced in the process:
1. Compiled code
There is a lot of functionality in SciPy and the Scikits that is not pure Python.
Performance-critical parts are written using compiled code extensions. These
parts are dependent on NumPy's internal memory representation, which makes them
CPU only. This prevents using the Array API standard to execute those functions
with CuPy. There is another project, uarray, for dispatching compiled code
which needs to be used along with the Array API standard to make it fully
generic.
See for instance following piece of code:
from scipy import sparsegraph = sparse.coo_matrix(<input_arrays>)
Here the sparse.coo_matrix is a C++ extension in the scipy.sparse module. We need to
dispatch to cupyx.scipy.sparse.coo_matrix for CuPy arrays and scipy.sparse.coo_matrix for NumPy
arrays. This is not possible via get_namespace. For this demo we have
added a workaround, until we have implemented the support for uarray-based
backends in SciPy. The workaround looks something like this for CuPy:
xp, _ = get_namespace(<input_arrays>)if xp.__name__ == 'cupy.array_api': from cupyx.scipy import sparse as cupy_sparse coo_matrix = cupy_sparse.coo_matrixelse: coo_matrix = scipy.sparse.coo_matrixgraph = coo_matrix(<input_arrays>)
Note that this workaround is only valid for NumPy/CuPy arrays.
2. Not implemented functions
We encountered a number of NumPy functions used by our Greek coins demo which didn't have a direct equivalent in the Array API standard. This was mostly due to the fact that those functions are not generic enough to be defined in the Array API. Some examples of unimplemented functions that we encountered during this exercise:
np.atleast_3dnp.stridesnp.realnp.clip
For some of these the solution was to reimplement an equivalent function, for
the remaining ones the workaround was using the library-specific NumPy/CuPy
APIs before converting back to the Array API standard-compliant Array object.
3. Inconsistencies between the NumPy API and the Array API standard
Although the standard has managed to get good coverage of the NumPy API, there
are places where there are inconsistencies between the two. This may be either
function behaviour that is missing or different, or function or parameter names
don't match (e.g., concat in the standard instead of np.concatenate).
Here is an example of a naming inconsistency between NumPy and the Array API standard:
In [1]: import numpy as npIn [2]: import numpy.array_api as npx# Numpy APIIn [3]: np.concatenateOut[3]: <function numpy.concatenate># Array APIIn [4]: npx.concatOut[4]: <function numpy.array_api._manipulation_functions.concat...>
And here is an example of a behavioral inconsistency for an indexing operation:
In [1]: import numpy as npIn [2]: import numpy.array_api as npx# Works with NumPy APIIn [3]: x = np.arange(10)In [4]: x[np.arange(2)]Out[4]: array([0, 1])# Doesn't Works with Array APIIn [5]: z = npx.arange(10)In [6]: z[npx.arange(2)]-----------------------------------------------------------------...IndexError: Non-zero dimensional integer array indices are not allowed in the array API namespace
Each of the inconsistencies can be worked around. Function renames may require some detective work by referring to the Array API standard documentation, but are typically easy code changes. Differences in behavior can be harder to deal with at times. The Array API standard aims to provide a set of functionality that's orthogonal but complete - so if it's possible to perform some array operation on accelerator devices, then there's typically a way to access it in the standard. In a few cases, integer indexing being one, work is still ongoing to extend the standard and we may open a feature request or contribute to an existing discussion while adding a workaround to our own code.
Results
After dealing with all the challenges above, our demo works with CuPy arrays as input. In this section, we will talk about about its performance on GPU vs. CPU.
We ran this on AMD GPUs as well as NVIDIA GPUs. Below we show plots comparing the runtime of the demo code on CPU and GPU as a function of input array size. The x-axis of the plot is the image dimension, i.e the dimension of the original image after rescaling it by a constant factor along both dimensions. For this demo the rescaling factors were: 0.1, 0.2, 0.4, 0.6, 0.8 and 1.
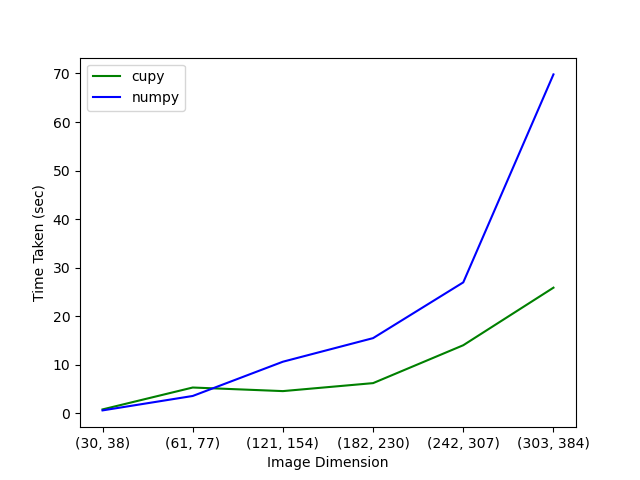
On AMD GPU:
This was run on a server with a AMD Instinct MI50 GPU with 32 GB of memory, and a CPU with 64 physical cores.
On NVIDIA GPU:
This was run on a NVIDIA TITAN RTX GPU with 24 GB of memory, and a CPU with 24 phyiscal cores.
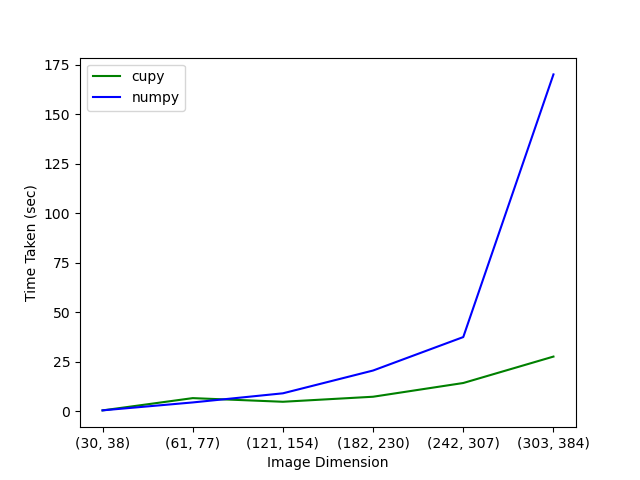
The GPU vs CPU plots show what you would expect: the computation is faster with CuPy (i.e. on GPU) compared to NumPy (i.e. on CPU) for larger image sizes. The computation on GPU is slower than on CPU for image sizes less than 61 x 77. This is due to the overhead of moving data to the device (GPU), which is significant compared to the time taken for actual computation. The larger the image, the longer the computation takes, and hence the less important the data transfer becomes and the larger the performance improvement from using a GPU.
Reproducing these results
The code and instructions to run the analysis above can be found in this repository: Quansight-Labs/array-api-gpu-demo.
The above analysis required changes in the following libraries:
cupyscipyscikit-learnscikit-image
The changes are present in the array-api-gpu-demo branch of @aktech's fork
of the above projects.
In the above mentioned repo, you can find the code with which we created Docker images for both NVIDIA & AMD platforms. The README also contains instructions for how to obtain the built Docker images from Docker Registry. Once you are inside the Docker container, running the demo is as simple as running:
python segmentation_performance.py
Running the ROCm container on a machine with an AMD GPU is done like this:
docker run -it --device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --group-add video ghcr.io/quansight-labs/array-api-gpu-demo-rocm:latest bash
Next Steps
At the moment we have only modified the functions we needed to be able to run our demo on GPU. There is of course a lot more functionality that can eventually be ported to support the Array API standard. The eventual goal of that is to make array-consuming libraries like SciPy, scikit-learn, and scikit-image fully compatible with multiple array libraries. A lot of work has been done in that direction already - but that's for a future post to talk about!
Acknowledgment
This demo work was part of a larger project to make PyData libraries work with multiple array libraries and thereby run on GPUs. This is a significant undertaking, and this work would not have been possible without funding from AMD for a team at Quansight Labs.