

Dataframe interchange protocol: cuDF implementation
Published October 21, 2021


iskode
Ismaël Koné
This is Ismaël Koné from Côte d'Ivoire (Ivory Coast). I am a fan of open source software.
In the next lines, I'll try to capture my experience at Quansight Labs as an intern working on the cuDF implementation of the dataframe interchange protocol.
We'll continue by motivating this project through details about cuDF and the dataframe interchange protocol.
cuDF - RAPIDS GPU Dataframes
cuDF is a dataframe library very much like pandas which operates on the GPU in order to benefit from its computing power. For more details about cuDF, please take a look at: https://rapids.ai/ and https://github.com/rapidsai/cudf.
To set the stage, recall that there are many dataframe libraries out there like: pandas, vaex, modin, dask/cudf-dask. Each one has its strengths and weaknesses. For example, vaex allows you to work with bigger than memory (RAM) datasets on a laptop, dask allows you to distribute computation across processes and cluster nodes and cudf-dask is its GPU counterpart.
Suppose you have a 300 GB dataset on your laptop and want to get some insights about it. A typical workflow can be:
import vaex# run some exploratory data analysis (EDA)import dask, cudf# take a sample of 3 GB# run some operations with Dask, then cuDF and compare performance.
Along the way, we load the dataset many times. We use the pair to_pandas/from_pandas to move from one dataframe library to another. Challenges arise with this practice:
-
possible memory overhead
-
high coupling with
pandasthat breaks an important software design pattern: Dependency Inversion Principle (DIP) which promotes dependencies at the abstract layers (interface) over the implementation layer.
The dataframe protocol comes into play as the interface specifying a common representation of dataframes and thus restores the broken dependency inversion design pattern.
Now, we can move from one dataframe library to another one using directly the from_dataframe method. No needs anymore to go through pandas. Note that this possible only among dataframe libraries supporting the protocol. Also, the protocol enforces zero-copy as much as possible which gets us rid of the possible memory overhead mentioned.
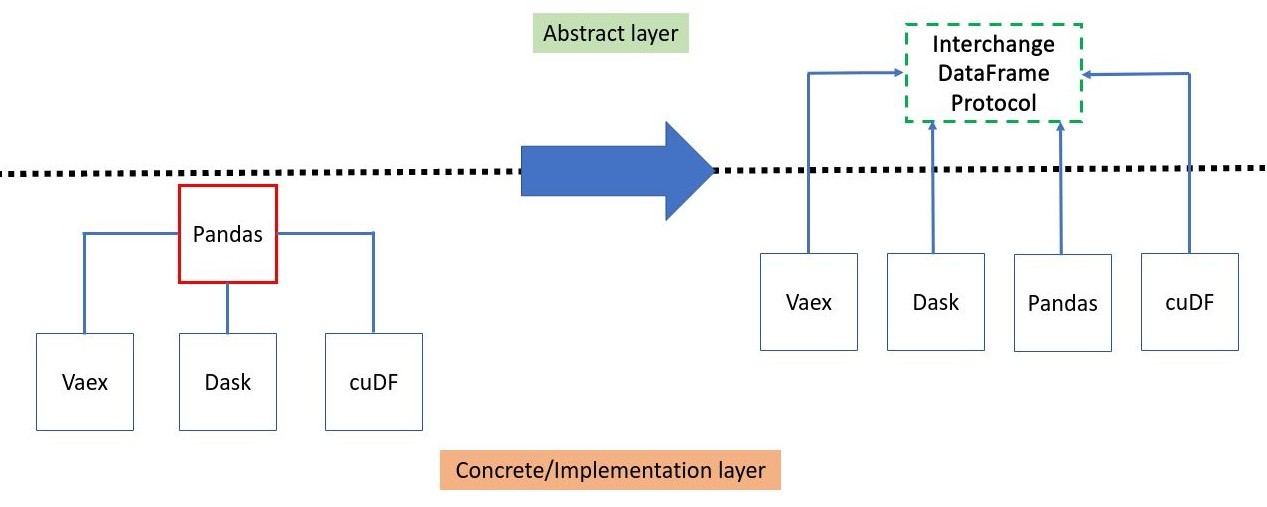 Design comparison without and with the dataframe interchange protocol API
Design comparison without and with the dataframe interchange protocol API
One of the main benefits of libraries complying with the dataframe interchange is that each library can evolve independently as long as the interface contract specification is followed and we are free from any dataframe library dependency as is the case with pandas. For more details about the purpose and scope of the protocol, please take a look at the DataFrame API documentation.
A brief description of the dataframe interchange protocol
The dataframe interchange protocol is in fact a composition of interfaces:
 Composition of the dataframe interchange protocol interfaces. Cardinality on links means "has 1 or more" of the Interfaces mentioned.
Composition of the dataframe interchange protocol interfaces. Cardinality on links means "has 1 or more" of the Interfaces mentioned.
So each library supporting the protocol should implement these 3 interfaces that can be described as follows:
-
DataFrame mainly exposes different methods to access/select columns (by name, index) and knowing the number of rows.
-
Column has methods to access the column data type, describe valid/missing values, exposes different buffers (data, validity and offset), chunks, ...etc.
-
Buffer has methods to describe the contiguous block of memory of the column data i.e device (GPU, CPU, ...), memory address, size, etc...
For more details, please have a look at Python code of the protocol interfaces and design concepts.
What is expected from cuDF interface implementation
Let's recap the protocol main features to be implemented in cuDF:
| Simple dtype | Complex dtype | Device | Missing values | Chunks |
|---|---|---|---|---|
| int | categorical | GPU | all dtypes (simple & complex) | single |
| uint8 | string | CPU | - | multiple |
| float | datetime | - | - | - |
The above table shows different features of the dataframe interchange protocol that that should be supported. In particular, we must support cuDF dataframes with column of various dtypes (simple and complex) and handle their missing values. Similarly, we must support dataframes from different devices like CPU as well.
Progress on the cuDF dataframe interchange protocol
Checked elements in the table below represent implemented features so far.
| Simple dtype | Complex dtype | Device | Missing values | Chunks |
|---|---|---|---|---|
| int | categorical | GPU | all supported dtypes (simple & complex) | single |
| uint8 | string | CPU | - | multiple |
| float | datetime | - | - | - |
| bool | - | - | - | - |
Note that we support CPU dataframes like pandas but since the protocol has not been integrated in the pandas repo, we can only test it locally. We've submitted this work as a Pull Request still under review, to rapidsai/cudf github repo.
Working cuDF code examples
We'll walk through a code example to the protocol in action as we round trip between pandas and cuDF.
We start by creating a cuDF dataframe object with columns named after supported dtypes:
import cudfimport cupy as cpdata = {'int': [1000, 2, 300, None], 'uint8': cp.array([0, 128, 255, 25], dtype=cp.uint8), 'float': [None, 2.5, None, 10], 'bool': [True, None, False, True], 'string': ['hello', '', None, 'always TDD.']}df = cudf.DataFrame(data)df['categorical'] = df['int'].astype('category')
Let's see the dataframe and make sure column dtypes are correctly recognized internally:
print(f'{df} \n\n'); df.info()
output:
int uint8 float bool string categorical 0 1000 0 <NA> True hello 1000 1 2 128 2.5 <NA> 2 2 300 255 <NA> False <NA> 300 3 <NA> 25 10.0 True always TDD. <NA> <class 'cudf.core.dataframe.DataFrame'> RangeIndex: 4 entries, 0 to 3 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 int 3 non-null int64 1 uint8 4 non-null uint8 2 float 2 non-null float64 3 bool 3 non-null bool 4 string 3 non-null object 5 categorical 3 non-null category dtypes: bool(1), category(1), float64(1), int64(1), object(1), uint8(1) memory usage: 393.0+ bytes
Now, we create the dataframe interchange protocol object to check that basic information like number of rows, column names and dtypes are accurate:
dfo = df.__dataframe__()print(f'{dfo}: {dfo.num_rows()} rows\n')print('Column\t Non-Null Count\t\t\t\t\t Dtype\n')for n, c in zip(dfo.column_names(), dfo.get_columns()): print(f'{n}\t\t {int(c.size - c.null_count)}\t\t{c.dtype}')
output:
<cudf.core.df_protocol._CuDFDataFrame object at 0x7f3edee0d8e0>: 4 rows Column Non-Null Count Dtype int 3 (<_DtypeKind.INT: 0>, 64, '<i8', '=') uint8 4 (<_DtypeKind.UINT: 1>, 8, '|u1', '|') float 2 (<_DtypeKind.FLOAT: 2>, 64, '<f8', '=') bool 3 (<_DtypeKind.BOOL: 20>, 8, '|b1', '|') string 3 (<_DtypeKind.STRING: 21>, 8, 'u', '=') categorical 3 (<_DtypeKind.CATEGORICAL: 23>, 8, '|u1', '=')
How about buffers? We will examine those of the 'float' column:
fcol = dfo.get_column_by_name('float')buffers = fcol.get_buffers()for k in buffers: print(f'{k}: {buffers[k]}\n')
output:
data: (CuDFBuffer({'bufsize': 32, 'ptr': 140704936368128, 'dlpack': <capsule object "dltensor" at 0x7ff893505e40>, 'device': 'CUDA'}), (<_DtypeKind.FLOAT: 2>, 64, '<f8', '=')) validity: (CuDFBuffer({'bufsize': 512, 'ptr': 140704936365568, 'dlpack': <capsule object "dltensor" at 0x7ff893505e40>, 'device': 'CUDA'}), (<_DtypeKind.UINT: 1>, 8, 'C', '=')) offsets: None
We can notice the column dtype <_DtypeKind.FLOAT: 2> from the data buffer and the dtype of the validity mask which is always<_DtypeKind.UINT: 1> here. Finally there is no offset buffer as it is reserved to variable-length data like string.
Let's retrieve data and validity arrays from their buffers using the DLPack protocol and compare with the column itself:
data_buffer = fcol.get_buffers()['data'][0]validity_buffer = fcol.get_buffers()['validity'][0]data = cp.fromDlpack(data_buffer.__dlpack__())validity = cp.fromDlpack(validity_buffer.__dlpack__())print(f'column: {df.float}')print(f'data: {data}')print(f'validity: {validity}')
output:
float column 0 <NA> 1 2.5 2 <NA> 3 10.0 Name: float, dtype: float64 data: [ 0. 2.5 0. 10. ] validity: [0 1 0 1]
Comparing the float column and the data, we see that values are similar except <NA> in the column correspond to 0 in the data array. In fact, at the buffer level, we encode missing values by a 'sentinel value' which is 0 here. This is where the validity array comes into play. Together with the data array, we are able to rebuild the column with missing values in their exact places. How? 0s in the validity array indicates places or indexes of missing values in the data and 1s indicates valid/non-missing values.
All this work is done by a helper function _from_dataframe which builds up an entire cuDF dataframe from a dataframe interchange object:
from cudf.core.df_protocol import _from_dataframedf_rebuilt = _from_dataframe(dfo)print(f'rebuilt df\n----------\n{df_rebuilt}\n')print(f'df\n--\n{df}')
output:
rebuilt df ---------- int uint8 float bool string categorical 0 1000 0 <NA> True hello 1000 1 2 128 2.5 <NA> 2 2 300 255 <NA> False <NA> 300 3 <NA> 25 10.0 True always TDD. <NA> df -- int uint8 float bool string categorical 0 1000 0 <NA> True hello 1000 1 2 128 2.5 <NA> 2 2 300 255 <NA> False <NA> 300 3 <NA> 25 10.0 True always TDD. <NA>
We just went over a roundtrip demo from a cuDF dataframe to the dataframe interchange object. Then we saw how to build a cuDF dataframe object from the dataframe interchange object. Along the way, we've checked the integrity of the data.
Lessons learned
Diversity advantage
Many studies show the benefits and better performance of diverse teams. My experience in this project was the CONTRIBUTING.md(old version) document on the repository which was very unclear for me as a newcomer. Following my mentors' advice (Kshiteej Kalambarkar and Ralf Gommers), I've opened an issue where I've shared my thoughts and kept asking clarifications which ended up in a (merged) PR to restructure the CONTRIBUTING.md (current version) document to make it clearer.
Thus, a diversity of levels (experts, newcomers, etc...) ensures an inclusive environment where everyone can find their way easily.
Test Driven Development (TDD)
This process has been very helpful during this project. I've noticed my slowness on days where I've started developing features before writing any test. I kept going back and forth in the code base to ensure the coherence of different pieces of code written for that feature. However, when writing tests I felt the possibility to express all my expectations across different test cases then writing code for each one at a time. In this process, I felt like the tests pointed out next place on the code base where they might be something wrong.
Collaboration, speaking out is very helpful
Sometimes, when stumbling upon a problem, just speaking out or sharing the problem to someone else opens your eyes to a possible solution. This happened to me countless times when discussing with my mentor Kshiteej Kalambarkar and my colleague Alenka Frim whose project is very close to mine. Otherwise, external inputs combined with ours will definitely be better than ours alone.
Patience and Perseverence
It is well known that configuring and installing drivers to work with GPU is not an easy task. During this internship I've been rebuilding the cuDF library many times and encountered multiple issues. I came up with a recipe which is:
- seek help after around 40 minutes of debugging even if you have more ideas to try.
- When asking for help, do share what you've tried and other ideas to try.
Speaking out can reveal some gaps as previously mentioned.
When something is missing, make an attempt to fix it. If it goes well, that'll be a contribution. That happened to me when trying to unpack bits with bitorder='little' as in numpy, using cupy instead. I've ended up submitting a (merged) Pull Request to CuPy.
Final Thanks and Gratitude
-
I'm very grateful to the team that works hard to bring up these internships in particular to my mentors Kshiteej Kalambarkar and Ralf Gommers as well as Ashwin Srinath from rapidsai/cudf;
-
I'm very glad to take part of this 1st cohort of interns at Quansight Labs;
-
I'm very happy be part of this warm and welcoming environment;
-
I'm proud of what this environment helps me achieve.

