
Array API Support in scikit-learn
Published September 19, 2023


thomasjpfan
Thomas J. Fan
The Consortium for Python Data APIs Standards developed the Array API standard, which aims to define consistent behavior between the ecosystem of array libraries, such as PyTorch, NumPy, and CuPy. The Array API standard enables libraries, such as scikit-learn, to write code once with the standard and have it work on multiple array libraries. With PyTorch tensors or CuPy arrays, it is now possible to run computations on accelerators, such as GPUs.
With the release of scikit-learn 1.3, we enabled experimental Array API support for a limited set of machine learning models. Array API support is gradually expanding to include more machine learning models and functionality on the development branch. Scikit-learn depends on the array_api_compat library for Array API support. array_api_compat extends the Array API standard to the main namespaces of NumPy's arrays, CuPy's arrays, and PyTorch's tensors. In this blog post, we cover scikit-learn's public interface for enabling Array API, the performance gain of running on an accelerator, and the challenges we faced when integrating Array API.
Benchmarks
Scikit-learn was initially developed to run on CPUs with NumPy arrays. With Array API support, a limited set of scikit-learn models and tools can now run with other array libraries and devices like GPUs. The following benchmark results are from running scikit-learn's LinearDiscriminantAnalysis using NumPy and PyTorch on a AMD 5950x CPU and PyTorch on a Nvidia RTX 3090 GPU.
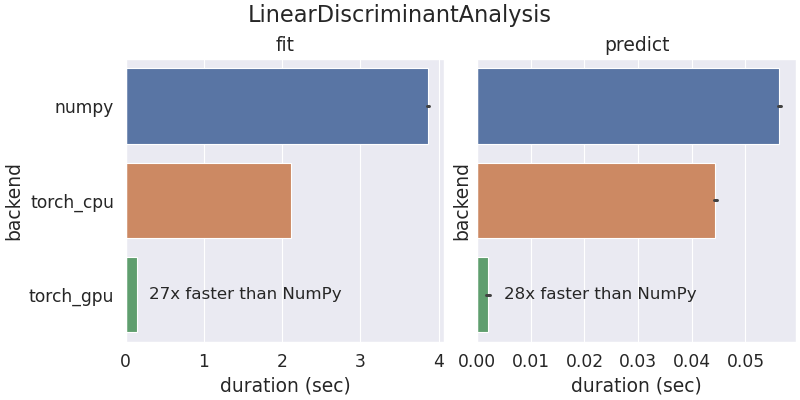
The training and prediction times are improved when using PyTorch compared to NumPy. Running the computation on PyTorch CPU tensors is faster than NumPy because PyTorch CPU operations are multi-threaded by default.
scikit-learn's Array API interface
Scikit-learn extended its experimental Array API support in version 1.3 to support NumPy's ndarrays, CuPy's ndarrays, and PyTorch's Tensors. By themselves, these array objects do not implement the Array API specification fully yet. To overcome this limitation, Quansight engineer Aaron Meurer led the development of array_api_compat to bridge any gaps and provide Array API compatibility for NumPy, CuPy, and PyTorch. Scikit-learn directly uses array_api_compat for its Array API support. There are two ways of enabling Array API in scikit-learn: through a global configuration and a context manager. The following example uses a context manager:
import sklearnfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.datasets import make_classificationimport torchX_np, y_np = make_classification(random_state=0, n_samples=500_000, n_features=300)X_torch_cpu, y_torch_cpu = torch.asarray(X_np), torch.asarray(y_np)with sklearn.config_context(array_api_dispatch=True): lda_torch_cpu = LinearDiscriminantAnalysis() lda_torch_cpu.fit(X_torch_cpu, y_torch_cpu) predictions = lda_torch_cpu.predict(X_torch_cpu)print(type(predictions))# <class 'torch.Tensor'>
Note how the estimator's output returns an array from the input's array library. This following example uses the global configuration and PyTorch Tensors on GPUs:
import sklearnimport torchsklearn.set_config(array_api_dispatch=True)X_torch_cuda = torch.asarray(X_np, device="cuda")y_torch_cuda = torch.asarray(y_np, device="cuda")lda_torch_cuda = LinearDiscriminantAnalysis()lda_torch_cuda.fit(X_torch_cuda, y_torch_cuda)predictions = lda_torch_cuda.predict(X_torch_cuda)print(predictions.device)# cuda:0
A common machine learning use case is to train a model on a GPU and then transfer it to a CPU for deployment. Scikit-learn provides a private utility function to handle this device movement:
from sklearn.utils._array_api import _estimator_with_converted_arraystensor_to_ndarray = lambda array : array.cpu().numpy()lda_np = _estimator_with_converted_arrays(lda_torch_cuda, tensor_to_ndarray)X_trans = lda_np.transform(X_np)print(type(X_trans))# <class 'numpy.ndarray'>
You can learn more about Scikit-learn's Array API support in their documentation.
Challenges
Adopting the Array API standard in scikit-learn was not a straightforward task and required us to overcome some challenges. In this section, we cover the two most significant challenges:
- The Array API Standard is a subset of NumPy's API.
- Compiled code that only runs on CPUs because it was written in C, C++, or Cython.
Array API Standard is a subset of NumPy's API
NumPy's API is extensive and includes a vast amount of operations. By design, the Array API standard is a subset of the NumPy API. For functionality to be included in the Array API standard, it must be implemented by most array libraries and widely used. Scikit-learn's codebase was initially written to use NumPy's API. In order to adopt the Array API, we had to rewrite some NumPy functions in terms of Array API functions. For example, nanmin is not a part of the Array API standard, so we were required to implement it:
def _nanmin(X, axis=None): xp = get_array_namespace(X) if _is_numpy_namespace(xp): return xp.asarray(numpy.nanmin(X, axis=axis)) else: # Implements nanmin in terms of the Array API standard mask = xp.isnan(X) X = xp.min(xp.where(mask, ...), axis=axis) return X
The NumPy arrays are still dispatched to np.nanmin, while all other libraries go through an implementation that uses the Array API standard.
There is an open issue in the Array API repo to discuss bringing nanmin into the standard. Historically, this process of introducing new functionality has been successful. For example, take was introduced into the Array API standard in v2022.12, because we proposed it in the Array API repo. The community determined that selecting elements of an array with indices was a standard operation, so they introduced take into the updated standard.
The Array API standard includes optional extensions for linear algebra and Fourier transforms. These optional extensions are commonly implemented across array libraries, but are not required by the Array API standard. As a machine learning library, scikit-learn extensively use the linalg module for computation. The Array API standard for NumPy arrays will call numpy.linalg and not scipy.linalg, which has subtle differences. We decided to be conservative and maintain backward compatibility by dispatching NumPy arrays to SciPy:
def func(X): # True if Array API is enabled and input follows the standard is_array_api_compliant = ... if is_array_api_compliant: svd = xp.linalg.svd else: svd = scipy.linalg.svd # uses svd for computation
This implementation was a compromise to ensure that NumPy arrays go through the same code path as before and have the same performance characteristics as previous scikit-learn versions.
Compiled Code
Scikit-learn contains a mixture of Python code and compiled code in Cython, C, and C++. For example, typical machine learning algorithms such as random forests, linear models, and gradient boosted trees all have compiled code. Given that the Array API standard is a Python API, it is most productive to adapt scikit-learn's Python code to use the standard. This limitation restricts the amount of functionality that can take advantage of Array API.
Currently, scikit-learn contributors are experimenting with a plugin system to dispatch compiled code to external libraries. Although there is compiled code, Array API will still play a critical role to get the plugin system up and running. For example, scikit-learn commonly preforms computation in Python before and after dispatching to an external library:
def fit(self, X, y): X_prep, y_prep = preprocess_X_y(X, y) model_state_array = plugin_dispatched_op(X_prep, y_prep) self.model_state_post = post_process(model_state_array)
With plugins, the dispatched code will ingest and return arrays that follow the Array API standard. The standard defines a common Python interface for preprocessing and postprocessing arrays.
Conclusion
In recent years, there has been increasing usage of accelerators for computation in many domains. The array API standard gives Python libraries like scikit-learn access to these accelerators with the same source code. Depending on your code, there are various challenges for adopting Array API, but there are performance and compatibility benefits from using the API. If you observe any limitations, you are welcome to open issues on their issue tracker. For more information about Array API, you may watch Aaron's SciPy presentation, read the SciPy proceedings paper, or read the Array API documentation.
This work was made possible by Meta funding the effort, enabling us to make progress on this topic quickly. This topic was a longer-term goal on scikit-learn's roadmap for quite some time. Similar steps are under way to incorporate the Array API Standard into SciPy. As the adoption of the Array API Standard increases, we aim to make it easier for domain libraries and their users to better utilize their hardware for computation.
I want to thank Aaron Meurer, Matthew Barber, and Ralf Gommers for the development of array_api_compat, which was a vital part of this project's success. I also want to thank Olivier Grisel and Tim Head for helping with this project and continuing to push forward on expanding support.

